I intended Week 1 to touch up any big issues that I’d noticed in the work I’d done so far – error management, and refining the AST and Variable Table.
Error Management and Imports
So, all compilers generally have multiple stages, and each stage may throw errors/warnings. Along with that, often, there may be some issues which aren’t explicitly compilation issues (eg. Maybe the compiler wasn’t able to read the file). A common error, is when a variable is misused – eg. we can’t do a select query from a single integer, we need a table!
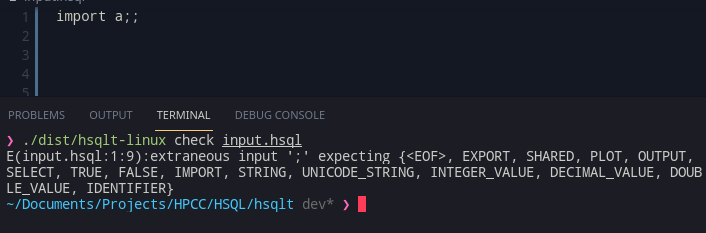
Consider this example file sample.hsql, which we are viewing in an IDE:
import a;
b = a;For a compiler that has to check types, what is the type of b? Of course, it is what the type of a is.
Now a, is only understandable, if I parse and process the whole of a.hsql and get its types out. However, if there’s some kind of error in a.hsql, we need to show it on the editor page for a.hsql, not sample.hsql.
Here’s the relevant method signature (one of the few that I use):
ErrorManager.push(e: TranslationError): voidTranslationError is a class that neatly wraps up where the issue is, what kind of an issue (Error/Warning/…) and what kind of error (Syntactic/Semantic/IO/…). One easy way, is to add a file:string as a member of TranslationError and hope for the best. As soon as I tried it, I realised there was a big issue; I have called .push() all over the codebase; there is no way I can expect every object and function to sanely track the file and report the issue accordingly.
So, the ErrorManager object itself has to track it.
One thing to realise, is that the ast generation function is recursive, especially. So, it will call itself eventually to resolve the other file (which happens when i’m trying to understand an import, more on that in a while).
Seeing recursion, an immediate thought is – a stack. A stack, can help deal with recursive things without requiring explicit recursion. So, a fileStack:string[] is good enough to act as a stack (All hail Javascript). Now, to mirror the AST calls, I decided a nice and easy way was to push the file context (the current filename) onto the stack at the beginning of the function, and then pop it at the end.
getAST(fileName:string = this.mainFile){
errorManager.pushFile(fileName);
// generate the AST of a file, errors may happen here - it calls itself eventually too if there is an import
errorManager.popFile();
}This simple trick, can be shown to ensure that the fileStack top will always be whatever file is being referred to (of course, unless we haven’t even started referring to a file yet!).
And, Bingo!
File Extension management
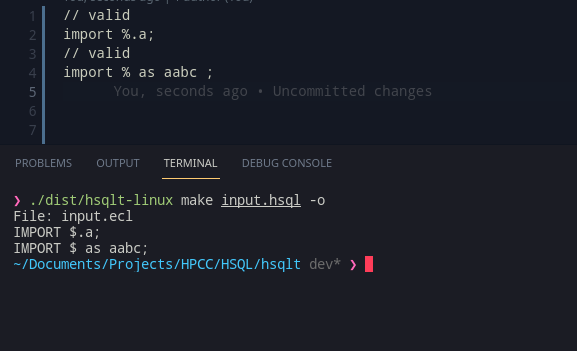
So, the HSQL (trans/com)piler also needs to make sure to rename file by extension easily. Node’s path extensions are perfect, but there is a slight important point to note: Pathnames are handled worry-free as long as we create them in the same system and consume them in the same system too! As in, if we use a Windows based system to create a path eg. C:\My\File.txt, it may not work properly if I try to consume it in a POSIX(Linux/Mac/…) system. Of course there are ways around that provided by the API, but we don’t need to worry about this edge case as all the pathnames that are entered during runtime are consumed by the same host itself.
Writing some small support code, we can use path.parse and path.format to easily rename files (Typescript does not like us doing it, but its valid way according to documentation), and voila!
AST, AST and more AST
ASTs were one of the primary goals that I have been working towards.
Internally of course it’ll be a data structure, but we can represent it something like this:
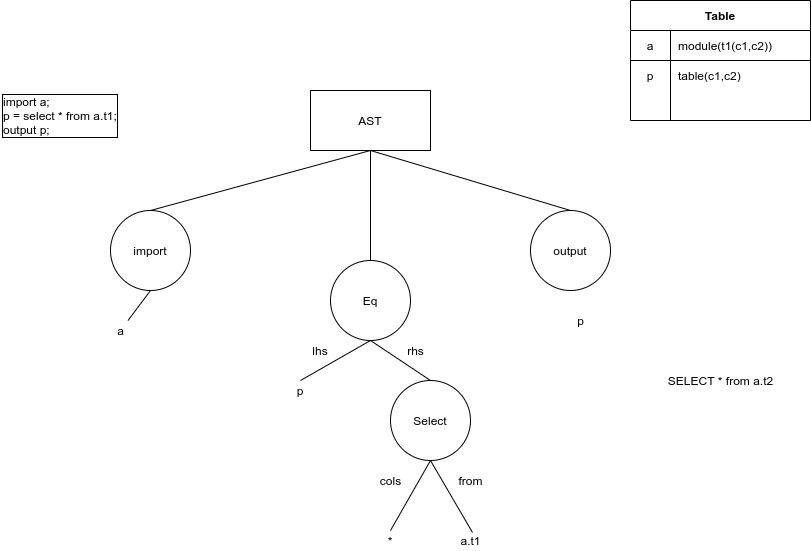
Note how much simpler it is than a parse tree. This does give me the added benefit of simplicity in the later stages; but its important to remember that the real star of the show is the little table on the right – a detailed type for every variable. More on that on some other time, but this representation should be mutable (something ANTLR parse trees don’t like being) and we can work with it a lot easier.
Variable table lookups
The Variable table, as of now contains a map of variables, their scope and what is their type. There’s two ways to introduce data into a program:
- Direct assignment – This is by creating a variable from some combination of literals. Eg.
a = 5. Understanding what is the type of a, is trivial(ish) in this case. - Imports – Imports is an important way to introduce data into a program. Eg.
import a. Figuring out the type of a, is a bit complex here. All we can know without any more context, we can only say thatais a module, no more and no less. We do not have any more information about the contents ofa; although for computation’s sake, we may assume that it has any and all members that are requested to be found in it. However, if its another HSQL file that isa.hsql, we can parse it and get the variables out of it. But, what about ECL?
ECL imports are a little tricky as we cant really get types out of ECL. So, the best we can do is try to see if a definition file is present (Let’s say a.ecl has some a.dhsql) that can give us more information on what a is.
Once you have data into the system, it can be propagated with assignments, and then, exported or given as an output.
Assignment ASTs
So, assignments are the core of this language.
y = f(x)This is a nice pseudocode on how assignments in general work.
Given f(x) is a function on input x, we can try to figure to figure out what y will be shaped like. As in,
If we know what x is (a table? a singular value?) and we know what f is and how it transforms x, we can figure out what the shape of y is.
Eg.
a = b;This is where we don’t really have special modifying function, but just an assignment. Whatever b is, a is definitely the same type.
Now consider,
a = select c1,c2 from b;Now, here is a transformation function where if b is a table, a becomes a table with c1 and c2. If b is a singular value, then well, a is just invalid :P.
Carrying this knowledge over, we can say that assuming f(x) returns its data shape and whatever its AST node is, then our Eq node just has to create a new variable according to what the LHS has been defined as.
So to start with, I created the AST for only direct assignments.
To do this, its easy to find the type of f(x) = x here, as its just a lookup into the variable table to figure out the type, which we understood earlier.
Putting this in terms of code, is really easy for the first part. The particular part for assignment need only take the data type, and create a new variable as per lhs, and hope that the parse tree visitor has created the AST node for the RHS and has validated it (which returns its AST node, and data type).
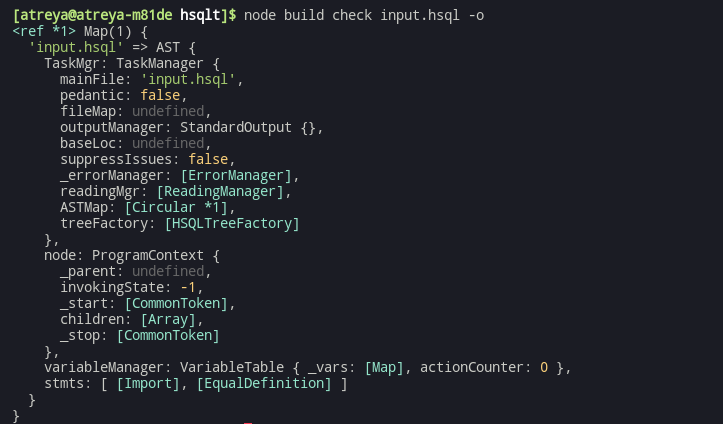
stmts, which is the root AST node’s childrenOf course the image may not show it, but the RHS is contained as a child node of the Assignment section.
Call stack and a lesson on stack traces
Nice! ASTs are conceptually working. But I try to generate code, and I see this:
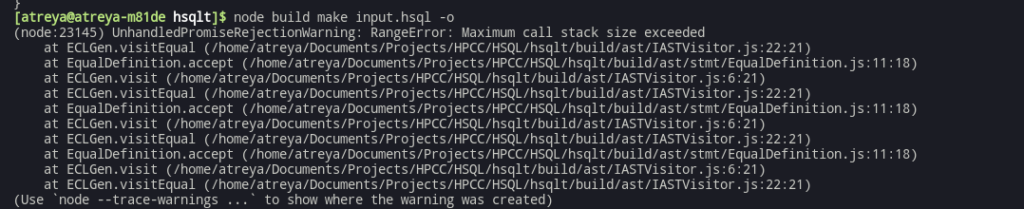
All right, looking at the stack trace, its becomes obvious what happened here, visit keeps getting called. And since I haven’t yet added code generation for the equal statement, the mistake/oversight becomes obvious – if a visit<something>() isn’t defined, it will call visit() as a fallback. But, visit() calls accept() which calls the required visit<something>(). The week is getting scarily close to the end so after finding out a fix that will work for me, I decide to pick it up first thing next week 😛 .
Winding up and getting ready for next week
So, the first week for me was interesting as I had to get a few things ready, and had to transfer over some work. But as soon as that was ready, we were ready for some quality work. With all this over, the main focus next week is to –
- Get Codegeneration fixed – This will require some redesign of the codegeneration class
- Implement a basic Output statement atleast – Output statements can help us get to testing faster.
- Look at VSCode extensions – Try to get a reasonable extension started!
- Syntax and workflow ideas – There can never be enough looking at syntax and seeing what is the best syntax for doing something!