This week’s plans were to essentially work on and implement the PLOT statement, and then to see how to update the TextMate Grammar and add in the new syntax.
Plots
Continuing from last week, we have auto-imports and an AST for Plots. With some little code generation, we can have a functioning PLOT statement.
Here’s the implementation I ended up choosing out of the 3 possible ways:
PARALLEL(OUTPUT(,,NAMED('<name>')),<module>.<function template>);PARALLEL allows for the actions to be executed in parallel, or rather, parallel given the best ordering that the ECL Compiler finds.
The code generation section was added in using this above idea, and care was taken to not emit the plot statement if the plot method was not found (and also raise an error) – as in such a case no template for the function call would be found.
Let’s take this sample code for reference
import marks;
-- lets get all the average marks of each subject
counting = select DISTINCT subid,AVG(marks) as avgmarks from marks.marks group by subid;
// join this to get the subject names
marksJoined = select * from counting join marks.subs on counting.subid=marks.subs.subid;
output counting title marksAvg;
// filter out what we need for plotting
marksPlottable = select subname, avgmarks from marksJoined;
// some different plots
PLOT from marksPlottable title hello type bar;
PLOT from marksPlottable title hello2 type bubble;Doing some sample codegeneration after implementation, we get this translation:
IMPORT Visualizer;
IMPORT marks;
__r_action_0 := FUNCTION
__r_action_1 := TABLE(marks.marks,{ subid,avgmarks := AVE(GROUP,marks) },subid);
__r_action_2 := DEDUP(__r_action_1,ALL);
RETURN __r_action_2;
END;
counting := __r_action_0;
__r_action_3 := FUNCTION
somesource := JOIN(counting,marks.subs,LEFT.subid = RIGHT.subid);
__r_action_4 := TABLE(somesource,{ somesource });
RETURN __r_action_4;
END;
marksJoined := __r_action_3;
OUTPUT(counting,,NAMED('marksAvg'));
__r_action_5 := FUNCTION
__r_action_6 := TABLE(marksJoined,{ subname,avgmarks });
RETURN __r_action_6;
END;
marksPlottable := __r_action_5;
PARALLEL(OUTPUT(marksPlottable,,NAMED('hello')),Visualizer.MultiD.bar('hello',,'hello'));
PARALLEL(OUTPUT(marksPlottable,,NAMED('hello2')),Visualizer.TwoD.Bubble('hello2',,'hello2'));Submitting this job to the local cluster, we can browse the Visualizations by going over to the workunit’s ‘Resources’ tab.
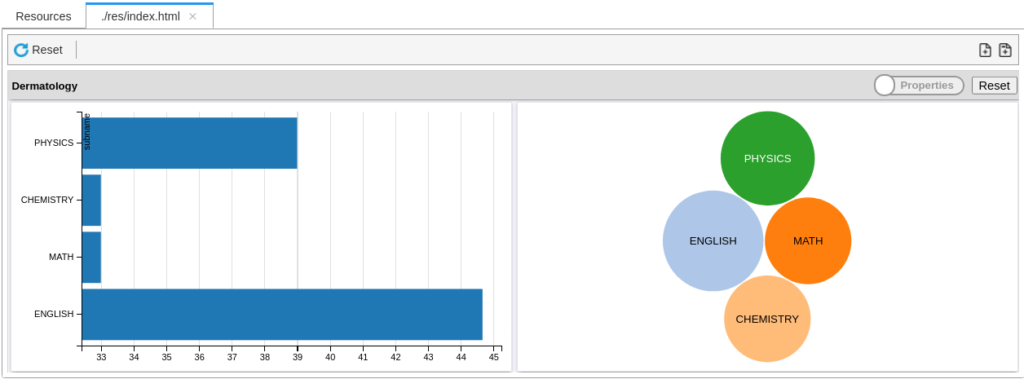
And, we have plots!
TextMate Grammars
The current Grammar that is being used is from the Javascript version, and is a bit finicky. When it was being set up, I used an approach similar to modelling a CFG – I mapped the ANTLR statements over to syntax mapping rules. That’s not the best idea.
I lookup and read a few grammars that were present for existing languages, giving some extra time to SQL. Turns out, most of them do not use that method above (Not a surprise to anyone).
When doing syntax highlighting, the developer also needs feedback as its being typed. If you wait for the whole statement to match, the whole statement will be in plain white until the ending ‘;’.
A much better way, is to recognize specific parts of the language, fast, and colour them accordingly.
Since HSQL has a lot of tokens, this is good and syntax highlighting can be done pretty effectively. Adding in the tokens for the language, we see some good highlighting, which the user can take advantage of as they are typing.
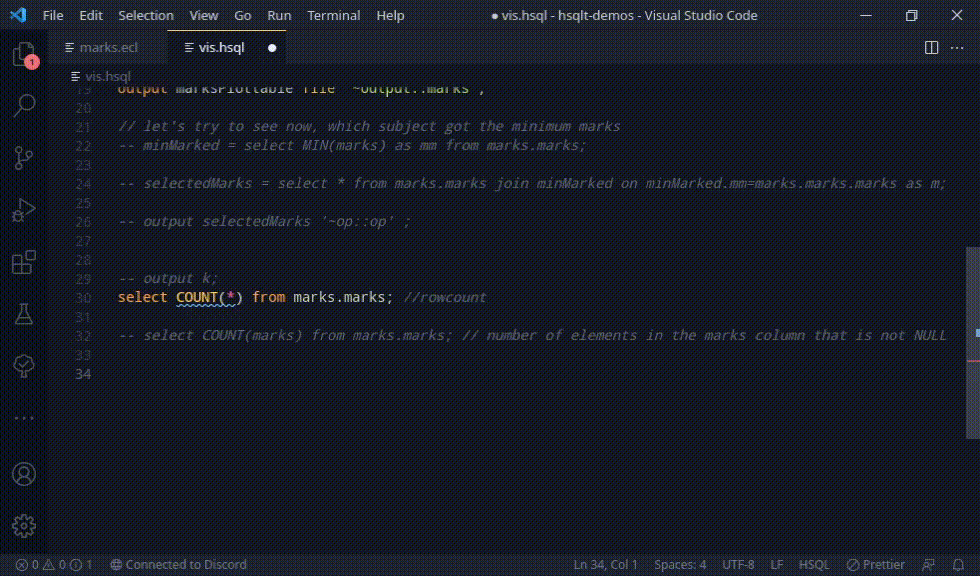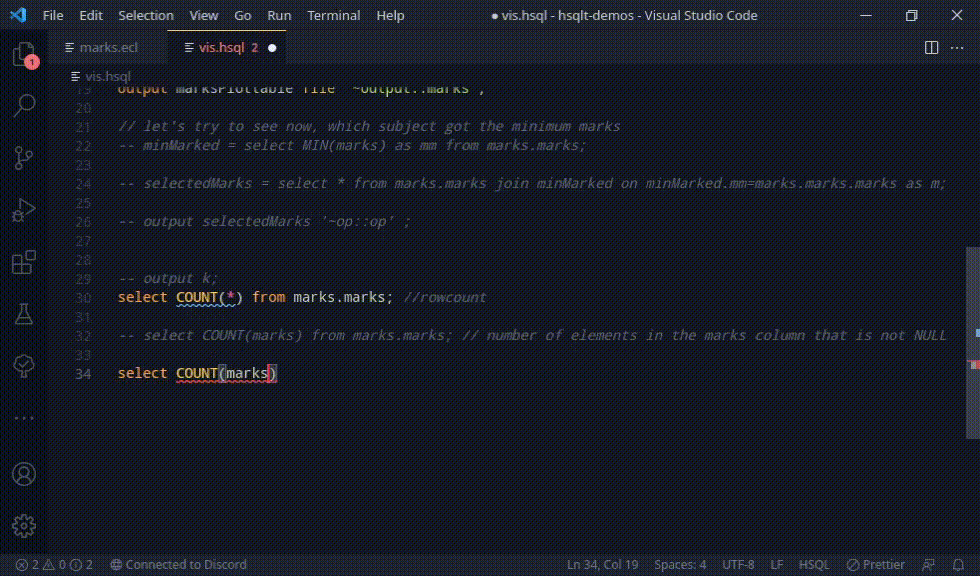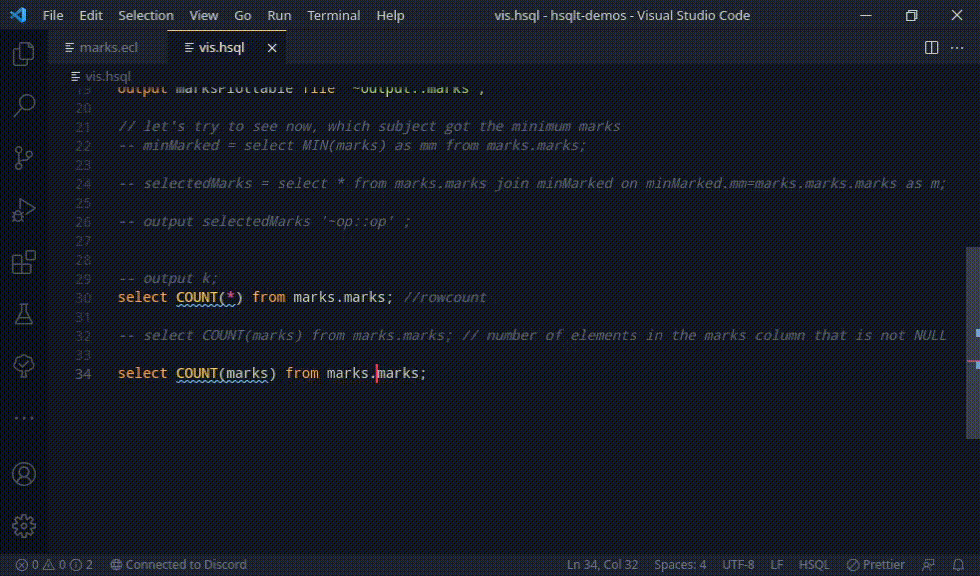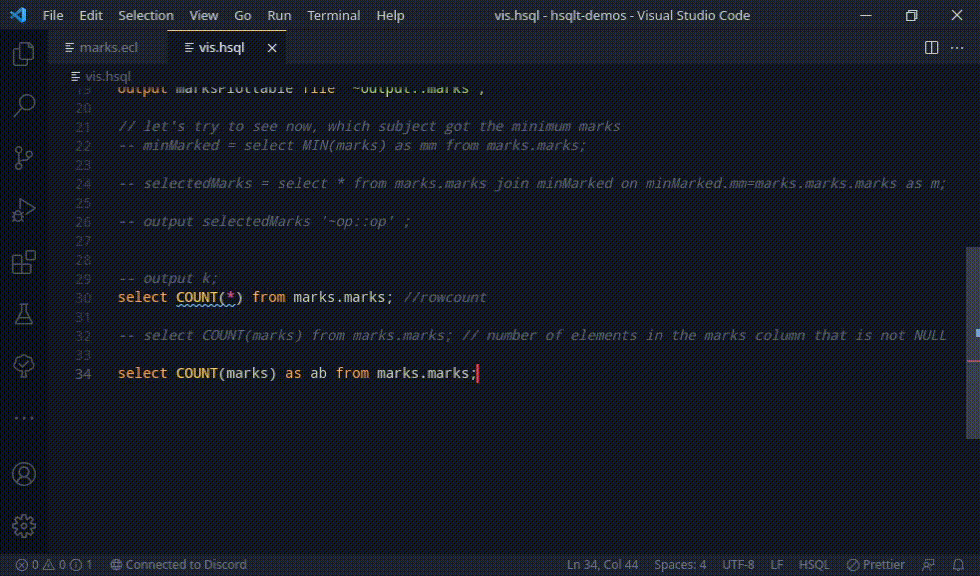
That took a while to get right, and as a result, this solves too issues at mind:
- Performance and complexity: The regexes and captures were difficult, long and annoying to read. By just identifying and colouring the tokens, the grammar is much simpler, and easy to read (and maintain).
- Tying into the ANTLR grammar: As the earlier TextMate grammar was identifying whole statements, the two grammars needed to be completely in sync, which is difficult considering the fact that the language is being actively worked on. Identifying token-wise simplifies things, and as we no longer dependent on the grammar, the grammar can be worked on and the syntax highlighting will still work very well. Only every now and then, new keywords that will be a part of the language need to be added into the TextMate grammar.
Wrapping up
Week 6 completes, and so do the midterm goals that we had planned for. The plan for the next week is roughly:
- Decide on the plan ahead
- Fix VSCode extension related bugs: Due to some breakage due to the addition of the File Providers in earlier weeks, quite a few bugsfixes have to be done for the HSQL extension.
- Add in DISTRIBUTE BY to Select – This would correspond to
DISTRIBUTEin ECL - Investigate grammar for
WRITE TOvariant of theOUTPUTstatement for writing to files.