This week has been a big week – extending SELECT to load up datasets from logical files, modules, functions, and running from a CLI was worked on. There’s a lot to uncover!
Select from dataset
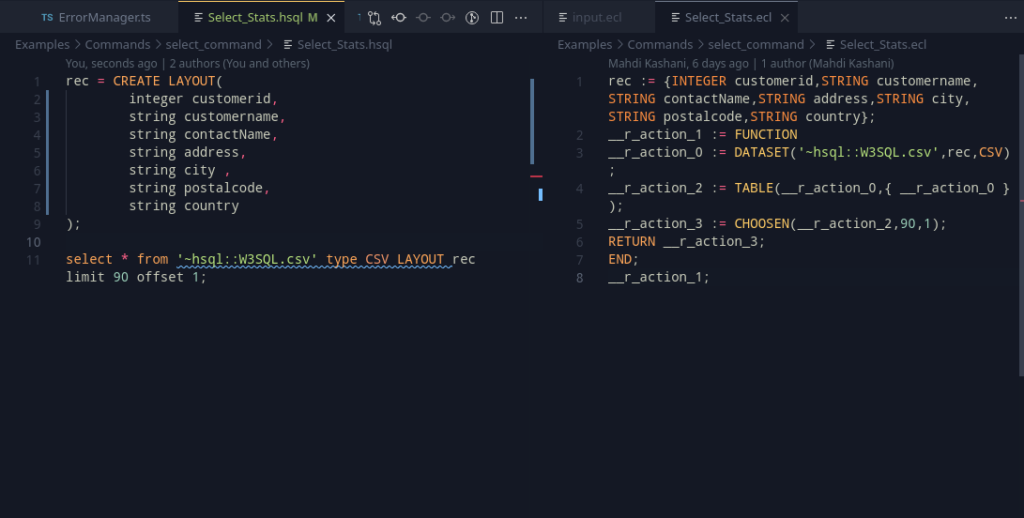
As layouts have now been introduced, one handy way of using select can be added in – loading up a dataset. The idea behind it is similar to how join works in HSQL – a new aliased variable that contains the necessary table. The shape of the table may be made out from the layout that was supplied to the command. Consider the following example:
Select * from '~file::file.thor' layout l1;This above example selects from the logical file using the layout l1. To see how this would translate to ECL, we can take the following example as what we want to achieve –
__r__action_x :=FUNCTION
src1 := DATASET('~file::file.thor',l1,THOR);
res := TABLE(src1,{src1});
return res;
END;
__r__action_x; // this is the end result-> assign it if neededTaking a look at SELECT, we can add support for ECL’s 4 supported types – XML, JSON, CSV, THOR. THOR is relatively easy to work with, but CSV files very commonly need to have their headers stripped (CSV(HEADING(1)) more precisely, when writing the ECL Code). This, might be a good point for SELECT’s offset clause to fit in. Currently it can only work with limit, but that restriction can be lifted later (by falling back to array subscripting).
Adding this SELECT Dataset as a separate node for the AST, we can treat it just like a join, and voila!
Modules
Modules are a great way to represent and structure code. Thankfully, as we’ve worked with select, the modelling style is similar here. The variable table entry for modules already exist, so its just a matter of adding in the right syntax. A good one to start would be
x = create module(
export k = 65;
shared j = 66;
l = 67;
);Currently the grammar still includes ECL’s three visibility modes, but we will look at that later.
When creating an AST node, we can create a new scope, and put our new variables in to create the module before popping them off to create the module entry; and while I thought this was easier, this was more of a “easier said than done”. However, thankfully, it didn’t take much longer since as I had mentioned, the data types were already in place.
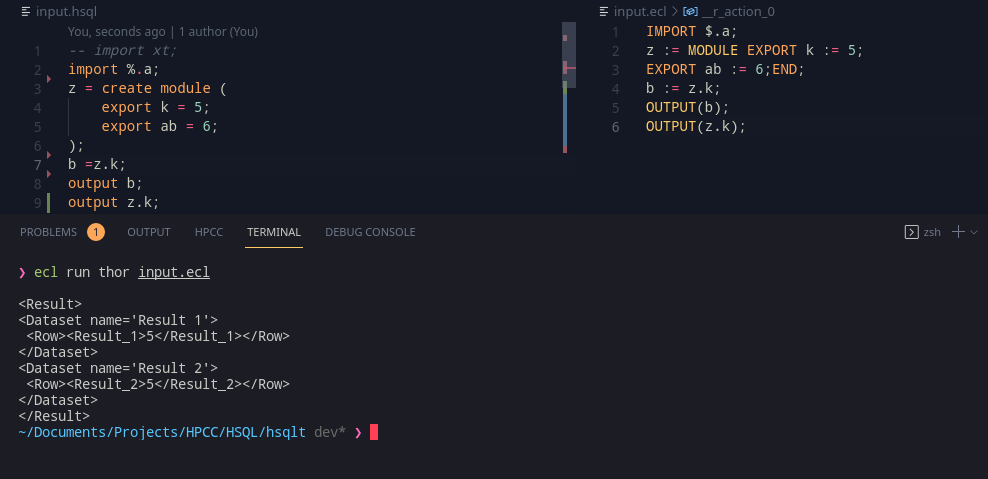
The variable table (or symbol table in regular compiler literature) can already resolve by the dot notation, so the type checking it works seamlessly and translates identically without any problems to ECL.
Functions
Functions are intended to be a nice way to reuse code. Implementation wise, they look pretty intimidating. How to start?
Well, let’s start at the grammar
create function <name> ([args]){
[body];
return <definition>;
};This is something to start with; it looks simple to work with and implement for the grammar. Going into the specifics, we can look at the arguments – there can be two types – the usual default primitive arguments, and a table. For the former, the standard C type rules work, for layouts, we can define them somewhat like this example:
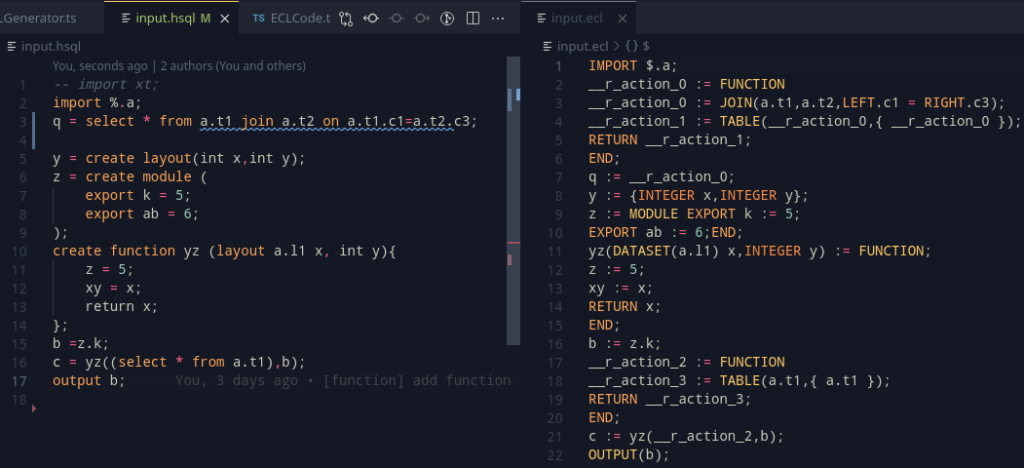
create function yz(layout l1 x,int y){
//...
};So, an important thing here, is to actually resolve this layout. Once we realise the layout, we can work with AST generation for the function in a way similar to that of the select statement – we can push a new scope into the function, and thankfully, as ECL supports variable shadowing for functions, we can push in the arguments as variables into the scope. Once that is over, we can pop the scope, and the resultant variables are gone! The arguments and the result type needs to be stored by the datatype though, and a function needs to be represented in the variable table too.
Adding all this in, only does half the job. Now that there’s functions, there needs to be a way to call them.
Function call
Function calls are rather important to be able to execute them. Now, the easiest is to model it after most of the programming languages:
x = somefunction(y,z);This function call can be checked during the AST Generation steps by the following steps:
- Locate the function from the variable table. If it cannot be found, throw an error.
- Match the function arguments. Does the length and the types match? If no, throw (lots of) errors.
- The function call node evaluates to the return type of the function now.
From here, the assignment node takes care of the returned type from there.
Adding all these steps, we can get something marvelous –
Running
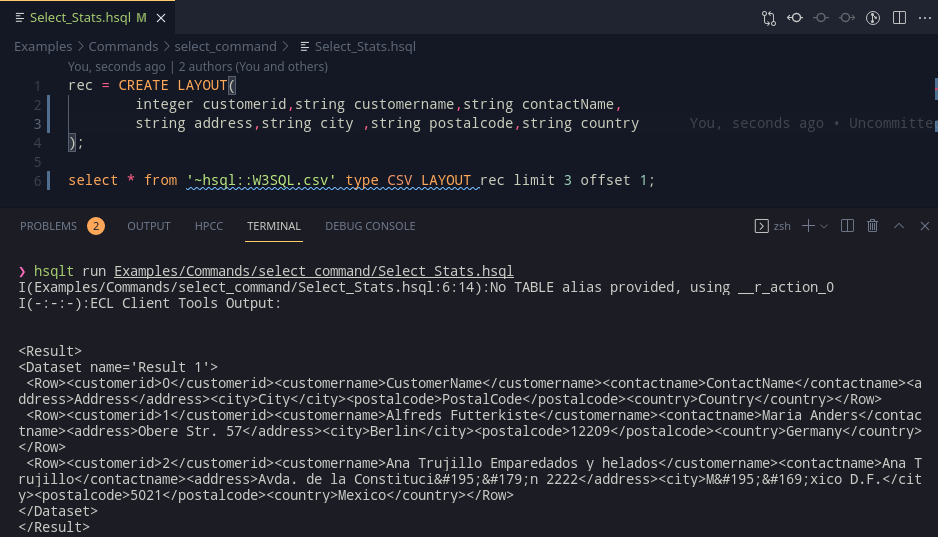
HSQLT already consults eclcc for getting the paths; this is a good opportunity to use this functionality to extend this and use ecl to compile and submit the resultant .ecl program. After checking if the outputs were produced from the previous code generation stage onto the filesystem, we can take the mainfile which stores the entry point for parsing, and submit that file’s ecl program to the cluster using the client tools. Using some nice stream processing, we can project the stdout and stderr of the child ecl process and get this nice result:
And there’s still more to go. Going over to the extension:
Code completion – Snippets
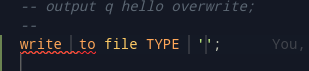
Snippets are an easy way to work with programs. VSCode snippets are a first step towards code completion. The example below can be typed with a simple write and the line will be filled in. Using TAB, the statement can be navigated and the appropriate sections can be filled in.
Code completion – Variable Resolving
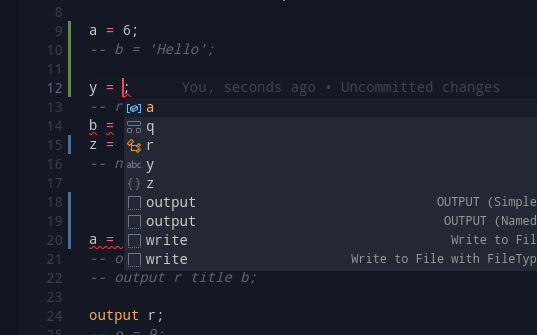
Variable resolving can be combined with Snippets to allow the user to write programd faster and more effectively. Pressing Ctl+Space currently brings up the current program’s table for auto complete. This, can be added by storing the last compilation’s variable table, and using that to find the possible variable entries.
Wrapping up
Oh dear, that was a lot of things in one week. The plans for the next week can roughly be summed up as –
- Look into implementing
TRAINandPREDICTstatements for Machine Learning. - Look into code generation, fix any glaring issues that result in incorrect code generation.