This week’s focus was more on getting train and predict working, the last two remaining statements. There were also some minor bugfixes.
Declarations
Declarations are used on the .dhsql files that we’ve worked on in the past. They’re a really nice candidate for adding in a way for bundles to indicate their train methods. However this time around; the ML_Core bundle is auto-loaded on import, but the actual machine learning methods are separated into many different bundles. Let’s see what’s need to actually make the machine learning statement work-
- The training template
- The prediction template
- The return type of the train statement
- The return type of the predict option
- Is discretization required?
- The model name (When predicting)
- The additional options that may be passed to train
- Are there any other imports?
So that’s 7 things that’s required. We can wrap it up into a whole declaration statement that the user need not worry about, but just expressive enough to list these.
From here, let’s take an example for LinearRegression to go about it.
declare linearregression as train '{bundleLoc}{ecldot}OLS({indep},{dep}).getModel' REAL RETURN TABLE(int wi,int id,int number,real value ) WHERE '{bundleLoc}{ecldot}OLS().predict({indep},{model})' RETURN TABLE(int wi,int id,int number,real value ) by LinearRegression;That’s a lot but what does it mean?
LinearRegressionis an available training method.- It uses
{bundleLoc}{ecldot}OLS({indep},{dep}).getModelas a template to train. The appropriate code gets filled in as required. (Yes, theecldotbecomes a., this is just to help with in-module methods, which may be a thing later but not right now). REAL– it does not require discretization.RETURN TABLE(int wi,int id,int number,real value )– The model is shaped this a table. It can also just beRETURN ANYTABLEif the shape is too annoying to list out or not required.- WHERE – switch over to the details for the prediction part
'{bundleLoc}{ecldot}OLS().predict({indep},{model})'– This is the template to predict withRETURN TABLE(int wi,int id,int number,real value )– The final result looks like this!- The method needs an import of
LinearRegressionto work.
Why are there two ‘return’s? That is because the model is not going to look like the prediction, and often, many machine learning methods give different shaped predictions (E.g. Logistic Regression returns a confidence too along with the result).
Adding these in, we get some good news of it working (Debugging is a god-send in Javascript programs, and VSCode’s JS Debug Terminal really makes it so much easier!). No outputs and screenshots yet though, there’s still some work left.
Tag Store
This is a good time to remember that there should be a way to tag variables in the variable table so that some information can be drawn out of them. Why is that useful?
Well, let’s take an example
- Easily find out which layout the table originated from.
- Tag a model (which is basically a table), as made with an ‘xyz’ method (eg. by LinearRegression)
This is actually easy. We can write up a simple Map wrapper and provide a way to pull out strings, numbers and booleans:
private map: Map<string, string | number | boolean>;
constructor() {
this.map = new Map();
}
getNum(key: string): number | undefined {
const entry = this.map.get(key);
if (typeof entry === 'number') { // only return numbers
return entry;
} else { // dont return non-numbers
return undefined;
}
}We can extend this for the other types also! Now to keep a track of the keys, we can have a nice static member in the class:
static trainStore = 'trainmethod' as const;Instead of having to remember the string, we can use this static const variable as well. We could also implement a whole type system and only allow specific keys, but that’s way too complex for a simple key value store.
Adding this as an element for our base data type DataType, we can now have a small k-v pair set for the variable tables. Note that here, WeakMaps were also a good way of doing this, but I do not wish to worry about equality of data types yet.
Train
Baby steps, and we are getting to Train. Passing the required arguments into train, the general way of generating the AST for the train node goes like –
- Find the train method. If it doesn’t exist, its time to throw an error.
- Check if the independent and dependent variables exist, and if they do, warn if they’re not tables. (Throw a huge error if they don’t exist to begin with.)
- Now, check the train arguments/options. Map the argument names with the datatypes and if the user has supplied them. If there has been a repeat passing of the same argument (name), or that given argument does not exist, throw an error.
- Dump all this information into the node, and done!
Doing all this, the code generation steps become easy! Just stack the variables (Similar to SELECT, discretize and add sequential ids if required, and fill it into the code template), and we have train!
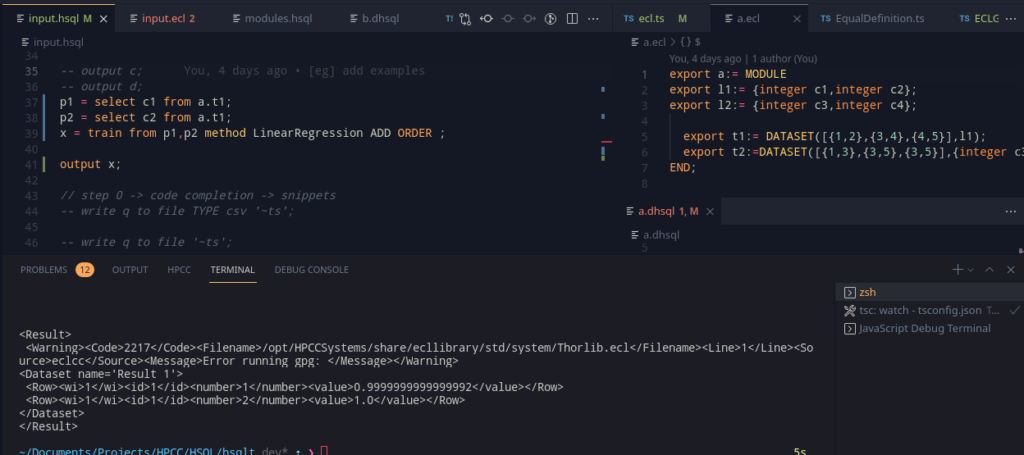
Predict
Predict follows a similar pattern – find the method, check if the arguments to it are tables, and then proceed to fill in the templates and the required steps using the stacking method from SELECT. Not going into a lot of detail as its the same, but here’s another thing.
We can use the tag store, and find the original model type, and this makes mentioning the model type optional. This allows for this nice pretty syntax!
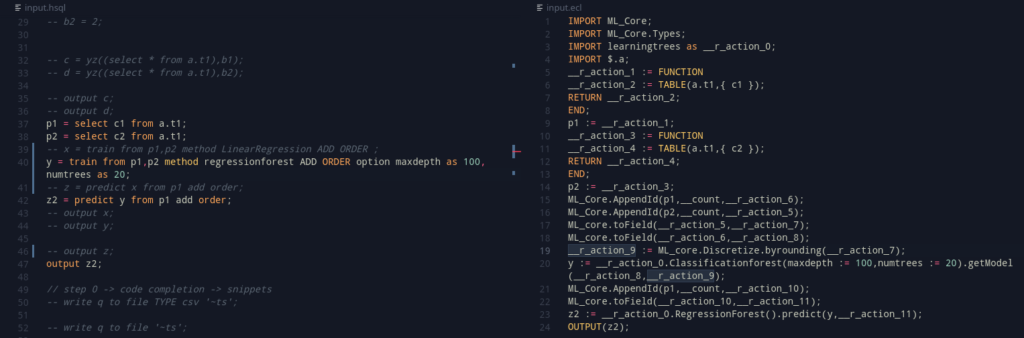
Of course, If you are keen enough, I have used incompatible train and predict templates (Classification and Regression Forest). This was just a way to check that by mistake, the same template wasn’t being used. This was fixed, and we now have LinearRegression, and Classification Forest as well! (2/?? done!)
Offset
I realised there was still something in SELECT that needs to be worked on – loading data from logical files.
The syntax currently looks like this
SELECT * from '~file.csv' TYPE CSV layout l1;Now, in ECL, a common pattern is to use
DATASET('~file.csv',l1,CSV(HEADING(1)));This removes the header part. The best way, for us is to use the offset clause. But, currently, it is only allowed a suffix to the limit clause. To deal with this, we can make this both optional.
However, the code generation stays almost the same, except for if only offset is specified. In such a case, we can fall back to using a array subscript method.
For example, offset 1, can translate to [1..]. This works well, and gives us a nice output!
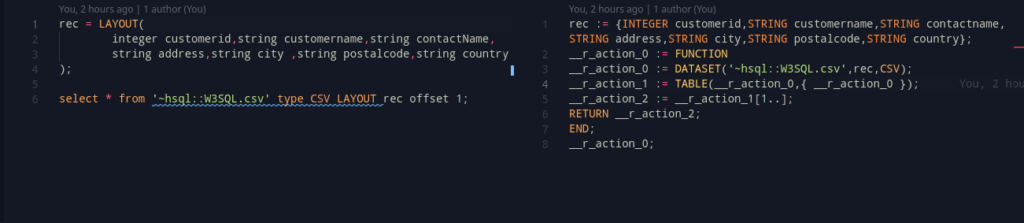
There’s one small issue though. ECL arrays are 1-indexed. In this case, its trivial too, we can just add a 1, and it’ll work perfectly.
offset 1 hence, should actually become [2..].
Winding up
This completes this week 10 too, and we’re almost there! Now, we can move towards week 11, with the following plans –
- Prepare for the final presentation next week
- Add more training methods!
- Maybe look around and find some nice ways to show the documentation and information about this project. Typedoc is already present in the project, but perhaps Docusaurus or Gitbooks would be good to use!