As a way to keep myself in track, I’ll create logs as I’m working on things. That way, I can be more regular with work. Anyways, this week will be getting a GUI.
GUI – getting a screen.
Well, here’s the plan. I’ll have to create the PPU (The GBA’s equivalent of a GPU and the CPU timers), so I can get an output. For that, I need a window.
SDL2 to the rescue. I’ve only used SDL2 in Rust (ref: porcel8).
Seems it was pretty easy to get it integrated after installing the SDL libraries.
find_package(SDL2 REQUIRED CONFIG REQUIRED COMPONENTS SDL2)
// link the library to our executable
target_link_libraries(advpi PRIVATE SDL2::SDL2)
And it builds successfully!
The screen
With some X11 forwarding, and adding some code to create a screen on output, we get an output!
Of course, for those of us using Fedora, which uses Wayland, XWayland needs to be enabled, and then on the , X11 forwarding needs to be enabled.
# Set this in /etc/ssh/sshd_config
X11Forwarding yes
Once that’s enabled, its just ssh-ing into the system, and then seeing a wonderful screen
ssh -X geemax # geemax is my test Pi
And, window!
Short end of a week
That’s it for now, I’m afraid.
In retrospect, working with the PI is a bit annoying and I’d like a totally local setup, and also decide between working on the PPU or the timers, whichever gets me to the boot splash screen faster!
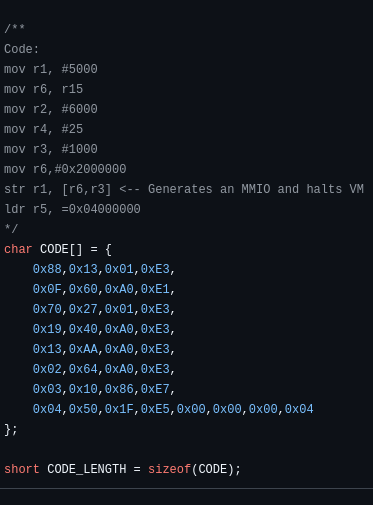
This week was a non-amusing transfer from C to C++ and adding the GBA BIOS.
BIOS Map
The Nintendo BIOS contains the basic code needed to initalize and use the GBA. After that the BIOS hands over control to the game that’s plugged in. My initial thought was to load the file into the game, then I remembered the golden word which haunted me last week – mmap. It was used to create the memory which is mapped to the guest VM.
So, I mmap-ed the BIOS file into the memory, then added it in.
Now its upto the kernel to manage it, and not my headache (for now).
Then I tried mapping the BIOS into the memory of the VM, and it segfaulted instantly. I changed some of the parameters to allow writes, and then it didn’t segfault, but the mmap didn’t go through.
After looking into the documentation, here’s the mistake I was mapping.
I was setting the slot to 0 for both the onboard memory (or where I was putting my code), and the BIOS page. They are actually different slots of memory, and need to be initialized as separate slots.
C++
I’m not used to C (and KVM and any of this) and it shows, so its probably a good idea to shift to C++ while I still can.
I wanted exceptions to handle unexpected failures, but I also didn’t want to model for releasing resources – a job better left for the compiler. C++ seems to be a better idea. I removed all the GOTOs, and got around to C++, then finally put an exception that helped me with my sanity.
class InitializationError : public std::exception {
private:
std::string message;
public:
InitializationError(std::string);
};
Being able to use exceptions along with constructors is useful. I’m aware that there’s a performance penalty, but it should be fine as long as I spend minimal time processing in my code (the kernel handles running the guest VM, not my code).
What’s next
The registers are still seemingly useful and garbage at the same time, but we shall see. Next week will mostly be travel and continued refactoring while I try to learn more, so next week will be week 5 essentially.
Summarizing what happens above, we “emulate” serial output device, by printing out what the VM wants to be printed, onto the console.
Cool, it works. We’re ready to start porting this onto the RPI.
Wait, how do I work with a RPI PI Zero 2 W?
Device setup
I had just bought this device. So let’s see what we need.
Some way to work with the project.
Running and testing on the RPI.
To run the project, I thought the easiest way would be to cross-compiling. So let’s get cross-compiling setup in Fedora.
And checking on Google, there’s a gcc arm64 cross compiler package:
Well, that’s a no then. Its not possible to cross compile actual userspace executables for ARM64 on x64 machines.
Then, let’s run it on the PI itself.
So, I decided that using some kind of remote development server is good. I tried VSCode, and the poor PI Zero 2 W collapsed given the weight of the remote server.
Well, then zed comes to the rescue. With a bit of tweaking, I connect to the PI over Tailscale, and open it using zed. Perfect.
I’m missing out on debugging, which will make it a pain, but that’s okay. Been through worse. Maybe it’ll finally push me to learn gdb.
Getting to run the Thing
Once that’s in and all things are done, we get to the first bit – compile errors all over the place. Some things are wrong.
Since the KVM API is different, the register names and the structures are different. Now it won’t compile.
KVM_GET_ALL_REGS and the corresponding don’t work. For some reason, its required to use KVM_SET_ONE_REG (and the corresponding individual get register).
Okay, all fixed.
There’s still a few things to fix. Namely, starting the CPU in 32 bit mode, and setting the initial PC and code.
Starting in 32 bit
The Cortex A53 starts in 64 bit as it is… a 64 bit processor. How do I instruct it to start in 32 bit mode? Rummaging through the KVM docs (Ctrl+F for “32-bit”), turns out before starting the CPU, I also need to initialize it with featuresets.
Why is it features[0]? I’m not sure I want to know why its addressed that way after spending way too much time trying to find out. The initialization also gives a bunch of useful features to initialize based on what’s required for us – I don’t want them as of now.
Now that the CPU is ready, something needs to be there to execute code.
Executable code
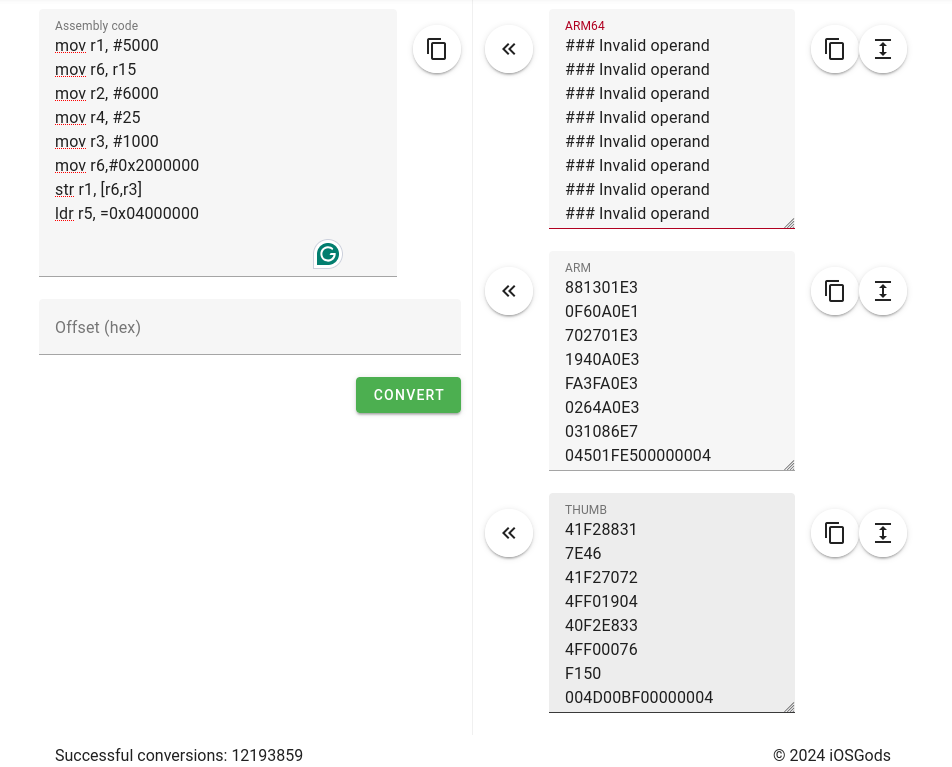
The days of writing code in assembly is gone (for the regular Software Engineer), but now, we need it again. Regular assemblers are too complex (for me as of now) to generate only the tiny snippets I need. This awesome online tool – “Online ARM to HEX Converter” does it all online. I put a small piece of code and let’s see what it does:
Wonderful – something. So I put this in an array and hope it works.
After all this, it still didn’t work (hint: endianness).
I got an MMIO, but was confused what it meant so I added this hideous snippet:
for (int r = 0; r < 16; r++){
printf("Got Registers: %d(%ld)\n", r,
getRegisterValue(gameboyKvmVM.vcpuFd, r));
}
We get this sad output and the program hangs; and I have no idea what’s going on:
So the registers were loaded correctly – and the code here was executed! But then R15 is 0? and the next LDR also didn’t generate an MMIO. Strange.
What’s next
As the week comes to a close, I’m getting a bit annoyed at managing resources, and would like (at least a bit of) help from the language. I’ve been coding in a “write the code then pray it works” – and have been ignoring cleanup, refactoring and reading the code again. Let’s take the time to do that, fix any issues. Hopefully by then I fix any faults in the program by cleaning up, or atleast learn more by then so I can.
I recently bought a Nintendo DS, and a Raspberry PI. Turns out the Nintendo DS can run Game Boy Advance (GBA) games, because they have the same CPU architecture.
NDS and a RPI Zero 2W
Well, the Raspberry PI isn’t too far off too. Does it mean I can just run Gameboy Advance Games on the RPI too?
Well, that’s what this series will go to show. This week is about understanding feasibility and what I will be using (and why). The later weeks should explore things in a bit more technical detail.
Can it GameBoy Advance?
Let’s see what we need, to run it on the Raspberry Pi Zero 2 W. I’ve chosen it because its very small, but runs the same chip as the RPi 1.
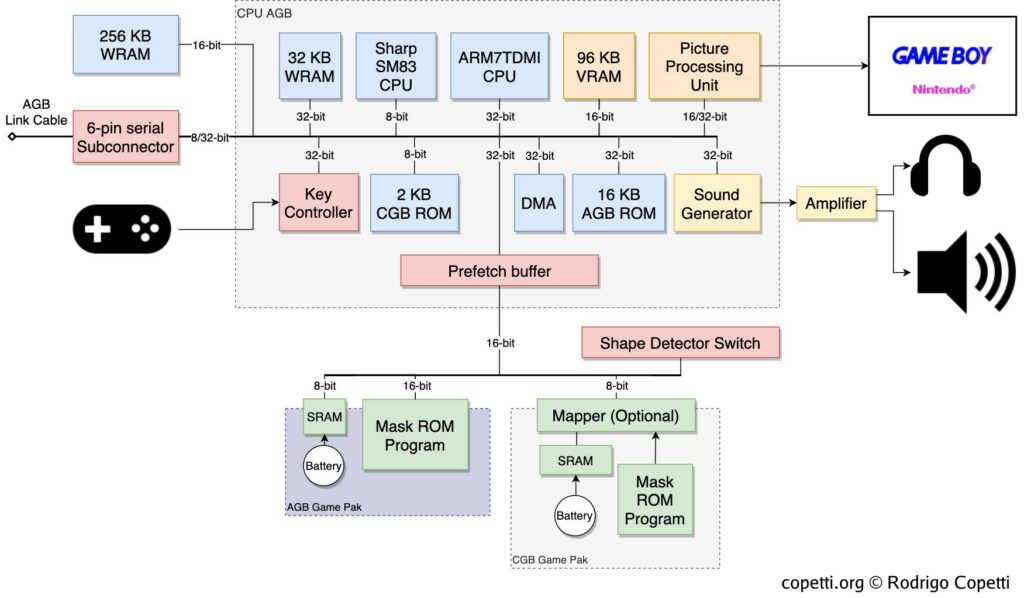
This beautiful article “Game Boy Advance Architecture” by Rodrigo Copetti explains what’s required for a GBA, but, let’s break it down and compare it to the RPI Zero 2 W.
Also, let’s think about the weird stuff like Display, Audio and Input later. Being able to run stuff is more important.
GBA Architecture – Rodrigo Copetti
So, let’s go by this order:
CPU
Memory
I/O
CPU
The Zero 2 W has CPU with 4 Cortex A53 cores, whereas the GBA used a ARM7TDMI chip. The A53 might be ancient, but the ARM7TDMI is comparatively prehistoric.
But, delving into the A53 Technical Reference Manual, it is entirely backwards compatible with the ARM7TDMI! The AArch32 instruction set, seems to be a renamed edition of what the older GBA CPU used to use.
Awesome, so the RPI CPU can natively run all these instructions, no problems.
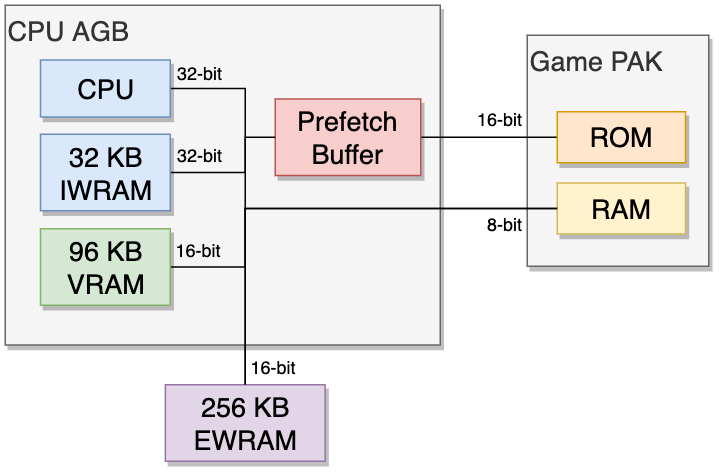
Memory
Memory – Rodrigo Copetti
Oof, it gets complicated here. There’s few things:
The AGB RAMs – They’re basically two different RAM chips, one smaller (32KB) and faster chip, and one larger (96KB) and slower chip.
The even slower (but massive) EWRAM
GamePAK memory – the Game Data
All of these items are laid out in the memory address space for the GBA CPU to access.
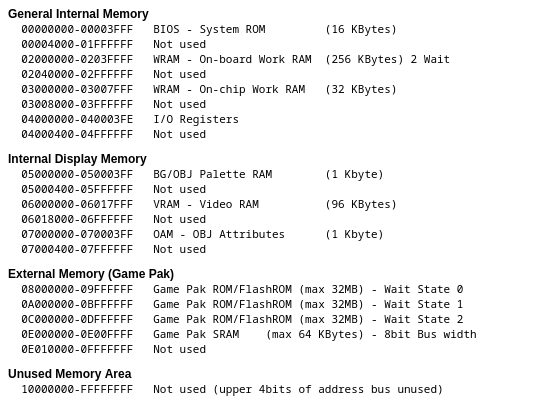
The GBA CPU accesses data through 32-bit addresses, and there’s a full address-layout map for fetching and storing data into these addresses.
Here’s the memory map from the no$gba documentation. (Ignore the Display Memory and I/O registers for now)
Intuitively, what this means is when the CPU tries to load data from 0x2000000, it loads the first byte of data from On-board WRAM. If it tries to use 0x3000000, it takes the first byte of data from the On-Chip Work RAM.
The RPI, unfortunately, has none of these mappings. It does however, has 512MB of RAM, which completely runs circles around what the GBA has for memory. Perhaps if there’s a way to create or simulate these mappings for the CPU to use?
I/O
We ignored the Display and IO memory mapping then, so we can discuss about it now. The display and the I/O is all memory-mapped. This means the data is directly available and usable via the memory.
The RPI, again, has none of this I/O. But it does have a lot of GPIO pins and display capabilities already, perhaps it can be “massaged” into the right shape and plugged into the GBA memory layout?
The initial hypothesis – Virtualization
Well, we had three finding:
The GBA and RPI can both execute ARM code
They differ in IO.
They differ in memory mapping.
Well, in these cases, people usually use virtualization. Hmm… That seems awfully inefficient. I might as well use an existing emulator then, where it’ll also replicate the behaviour of the CPU. Although…
Hardware-Assisted Virtualization
Hardware assisted virtualization is a featureset of newer CPUs, where the CPUs can run guest code directly, skipping the need to emulate CPUs in software. Intel provides HAXM, AMD provides AMD-V, and ARM provides… well, something similar, but not sure what the name is. Let’s see how to use it in practi-
No, I can’t understand any of that. Understandable.
Looking online how it works, I remembered/found this neat thing – KVM. Linux takes all these features, and abstracts these architectures into one API, the KVM API. This allows Linux Hosts to run Guest machines with Hardware Accelerated execution.
KVM allows setting memory spaces, setting device specifications and runs code on a virtualized CPU that runs on the machine using the Virtualization Extensions on the CPU. Anything devices need virtualization? KVM gives control back to you to implement it yourself.
What’s better, the RPI Zero 2 W supports KVM.
$ ls /dev/kvm
crw-rw---- 1 root kvm 10, 232 Dec 7 19:29 /dev/kvm
The Final Problem Statement
So, let’s distill all of this into two questions:
Can the GBA be run as a virtual machine on the Raspberry PI Zero 2 W?
Is there any benefit to virtualization, instead of complete emulation?
Thus, the project advpi is planned to run GBA code on the PI Zero 2 W, by using a virtual machine.
The IO will need to be adapted and emulated by the software as well.
Display, can be showed on a window on-screen, and the sound can be played on the pi as it has sound capabilities as well (given a speaker is attached to it).
Anything else, will be figured out as it comes. Let’s see how that goes.
What’s next week?
Setting up a workspace on a RPI.
Testing the KVM API to run some x86 code, as it is well-documented.
This week focused on finishing up documentation, a little bit of cleanup and one final task of implementation that would be helpful.
DISTINCT
The SELECT DISTINCT clause currently uses a DEDUP(x,ALL), which is notoriously slow for large tasks. Instead an alternative clause was suggested
TABLE(x,{<cols>},<cols>,MERGE);
//eg. for a t1 table with c1 and c2
TABLE(t1,{t1},c1,c2,MERGE);
This looks good!
But, the question is – how to get the columns c1 and c2 for the table t1? It may not always be known, or worse, the known type information may not be complete. Here, we are presented with two ways in which we can proceed with this information:
Stick with DEDUP all the time. It is slow, but it will work.
Use the new TABLE format, falling back to the DEDUP variant if type information given is not sufficient.
This is great, and it also incentives typing out ECL declarations, but it still feels as a compromise.
Template Language
Everything changed when I realised that ECL has a wonderful templating language. For a quick idea on what the point of a template language is, it can be used in a way similar to the preprocessor directives in C – macros that can be used to write ECL.
So, what can we do here? The good thing about writing macros is that since they are based off the same solution, the macro processor can work with data types in ECL very well, and also, can make ECL code.
So, can we write an expression that creates the c1,c2 expression, given that the table t1 is given?
Although I won’t go into the details of this interesting function macro (A macro whose contents are scoped), in essence, it can take a record, and put out a snippet of code that contains the columns delimited by comma.
Using __dedupParser
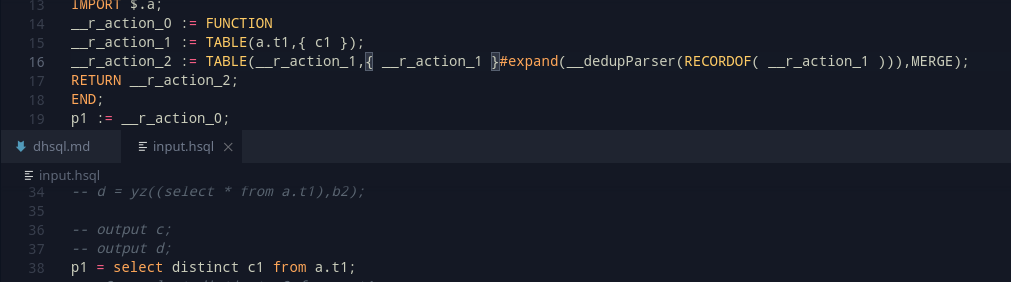
Although the naming isn’t accurate, we can inspect what the macro does by an example
Given a record R1, which contains two fields, f1 and f2 (Assume both as integer), then __dedupparser(r1) will create an ECL code snippet of “f1,f2,” (Notice the trailing comma). This works nicely with the RECORDOF declaration, which can help get the record associated with a recordset definition.
So, this brings something really useful, as we can now have this general code syntax –
This simple expression generalizes the entire TABLE function pretty effectively.
Adding this into code, it is important to remember that the function macro needs to be inserted separately, and most importantly, only once in a ECL file. This is better done by tracking whether a DISTINCT clause has been used in the program (Using an action like we had done earlier), and inserting the functionmacro definition at the top in this case. And with this, a good new improvement can be made to the SELECT’s DISTINCT clause.
Distinct now has shinier code!
This should perform much better, and work more efficiently.
Documentation
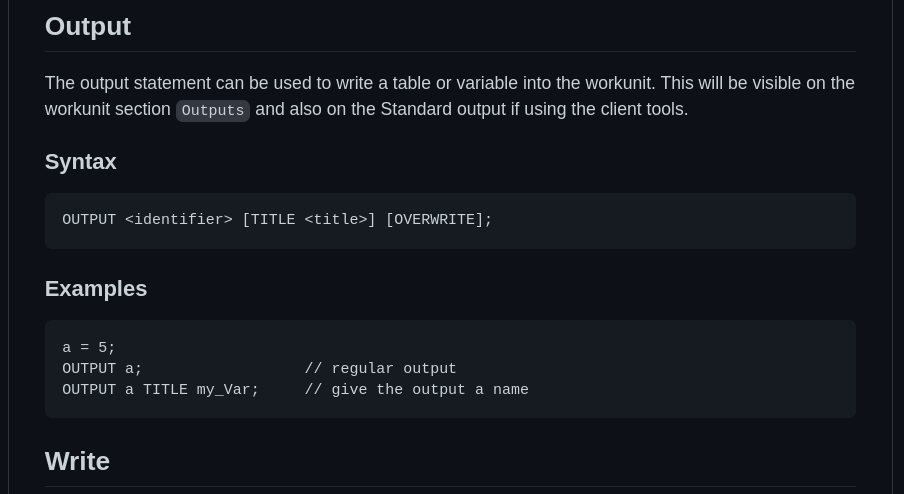
So far, some of the syntax was stored and referred personally by the use of notes, memory and grammar. Writing this down in essential as a way of keeping a record (More for others, and even more importantly, for yourself). So, keeping a document to denote the syntax available to the user is rather important.
Docs for OUTPUT!
Here, its important to lay out the syntax, but also present some usable examples that an explain what is going on with that code segment. (Yeap, for every single statement!)
Winding up!
With documentation, that ends a lot of the work that was there. In fact, its already Week 12, although it is still surprising how quickly time has passed during this period. My code thankfully doesn’t need extensive submission procedures as I was working on the dev branch, and work will continue on this “foundation”. It has been a wonderful 12 weeks of a learning and working process for me, and I would like to thank everybody at the HPCC Systems team for making it such an enjoyable process! Although this is all for now, I can only hope that there’s more to come!
This week, was adding some more Machine Learning Methods, and a final Presentation for the work I’ve done through this period!
Adding More Machine Learning Support
A set of other
A set of other training methods were also added. GLM was decided to be split into some of its more commonly used components. This expands the support to also include:
(Regression) Random Forest
Binomial Logistic Regression
GLM
DBScan
More model types!
This, is rather easy to do now that we have added declarations; there is a standard ML_Core.dhsql memory file, and this provides a nice way to provide built-in declarations.
Going from here, following the declaration syntax, we can add in a lot of the methods:
Here is a declaration for Classification forest
Predict-only methods
DBScan is a good one, as it is an unsupervised Machine Learning technique that does not fit into the traditional ‘train-predict’ idealogy. Here, the idea is have a variant of the predict statement that captures a syntax similar to train. Let’s model the statement as:
predict from <ind> method <methodtype> [ADD ORDER] [<trainoptions>];
Adding in the grammar, as most of the work is similar to train, we can add this in, and voila! A new statement for this form of machine learning!
DBScan!
Final Presentation
This is where a lot of the time was spent; I’ve been gathering and making examples for HSQL, and how it can be used, and on Thursday, we had a presentation on HSQL, what’s new and how it can be useful! (I will post more about it when I can!)
Wrapping up
As week 11 comes to an end, there are some things that may require documentation, and those are being looked at; and that’s about it! We still have to add some examples for the easy to use machine learning statements, and maybe also look at some code generation suggestions. (and perhaps even try to implement one!)
This week’s focus was more on getting train and predict working, the last two remaining statements. There were also some minor bugfixes.
Declarations
Declarations are used on the .dhsql files that we’ve worked on in the past. They’re a really nice candidate for adding in a way for bundles to indicate their train methods. However this time around; the ML_Core bundle is auto-loaded on import, but the actual machine learning methods are separated into many different bundles. Let’s see what’s need to actually make the machine learning statement work-
The training template
The prediction template
The return type of the train statement
The return type of the predict option
Is discretization required?
The model name (When predicting)
The additional options that may be passed to train
Are there any other imports?
So that’s 7 things that’s required. We can wrap it up into a whole declaration statement that the user need not worry about, but just expressive enough to list these.
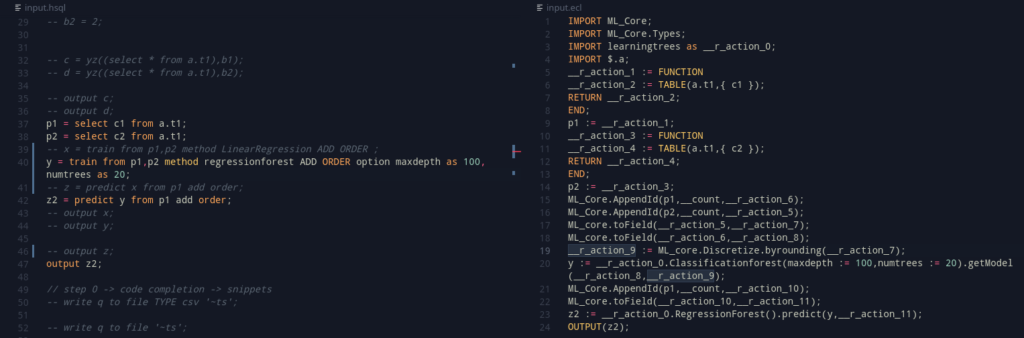
From here, let’s take an example for LinearRegression to go about it.
declare linearregression as train '{bundleLoc}{ecldot}OLS({indep},{dep}).getModel' REAL RETURN TABLE(int wi,int id,int number,real value ) WHERE '{bundleLoc}{ecldot}OLS().predict({indep},{model})' RETURN TABLE(int wi,int id,int number,real value ) by LinearRegression;
That’s a lot but what does it mean?
LinearRegression is an available training method.
It uses {bundleLoc}{ecldot}OLS({indep},{dep}).getModel as a template to train. The appropriate code gets filled in as required. (Yes, the ecldot becomes a ., this is just to help with in-module methods, which may be a thing later but not right now).
REAL – it does not require discretization.
RETURN TABLE(int wi,int id,int number,real value ) – The model is shaped this a table. It can also just be RETURN ANYTABLE if the shape is too annoying to list out or not required.
WHERE – switch over to the details for the prediction part
'{bundleLoc}{ecldot}OLS().predict({indep},{model})' – This is the template to predict with
RETURN TABLE(int wi,int id,int number,real value ) – The final result looks like this!
The method needs an import of LinearRegression to work.
Why are there two ‘return’s? That is because the model is not going to look like the prediction, and often, many machine learning methods give different shaped predictions (E.g. Logistic Regression returns a confidence too along with the result).
Adding these in, we get some good news of it working (Debugging is a god-send in Javascript programs, and VSCode’s JS Debug Terminal really makes it so much easier!). No outputs and screenshots yet though, there’s still some work left.
Tag Store
This is a good time to remember that there should be a way to tag variables in the variable table so that some information can be drawn out of them. Why is that useful?
Well, let’s take an example
Easily find out which layout the table originated from.
Tag a model (which is basically a table), as made with an ‘xyz’ method (eg. by LinearRegression)
This is actually easy. We can write up a simple Map wrapper and provide a way to pull out strings, numbers and booleans:
private map: Map<string, string | number | boolean>;
constructor() {
this.map = new Map();
}
getNum(key: string): number | undefined {
const entry = this.map.get(key);
if (typeof entry === 'number') { // only return numbers
return entry;
} else { // dont return non-numbers
return undefined;
}
}
We can extend this for the other types also! Now to keep a track of the keys, we can have a nice static member in the class:
static trainStore = 'trainmethod' as const;
Instead of having to remember the string, we can use this static const variable as well. We could also implement a whole type system and only allow specific keys, but that’s way too complex for a simple key value store.
Adding this as an element for our base data type DataType, we can now have a small k-v pair set for the variable tables. Note that here, WeakMaps were also a good way of doing this, but I do not wish to worry about equality of data types yet.
Train
Baby steps, and we are getting to Train. Passing the required arguments into train, the general way of generating the AST for the train node goes like –
Find the train method. If it doesn’t exist, its time to throw an error.
Check if the independent and dependent variables exist, and if they do, warn if they’re not tables. (Throw a huge error if they don’t exist to begin with.)
Now, check the train arguments/options. Map the argument names with the datatypes and if the user has supplied them. If there has been a repeat passing of the same argument (name), or that given argument does not exist, throw an error.
Dump all this information into the node, and done!
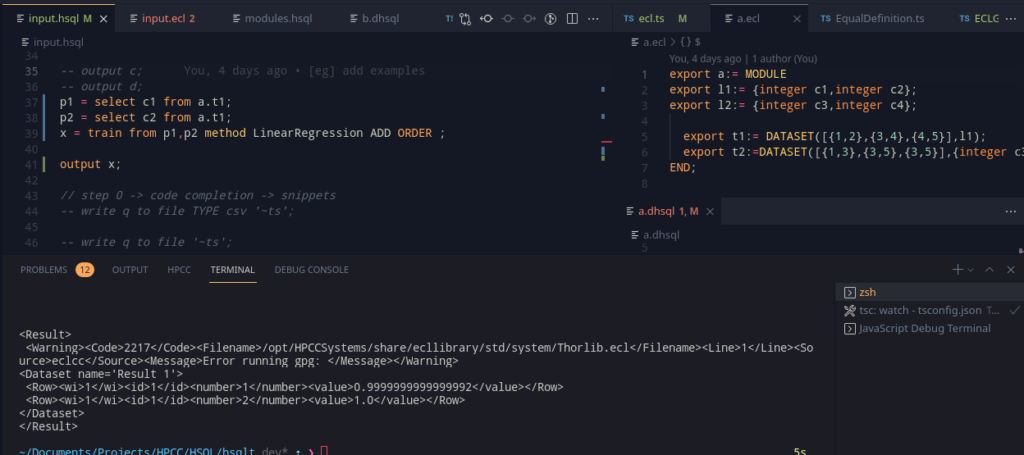
Doing all this, the code generation steps become easy! Just stack the variables (Similar to SELECT, discretize and add sequential ids if required, and fill it into the code template), and we have train!
Three days of effort and I can finally say that 2 = 1*1+1! (/s)
Predict
Predict follows a similar pattern – find the method, check if the arguments to it are tables, and then proceed to fill in the templates and the required steps using the stacking method from SELECT. Not going into a lot of detail as its the same, but here’s another thing.
We can use the tag store, and find the original model type, and this makes mentioning the model type optional. This allows for this nice pretty syntax!
Train, Predict, and code generation!
Of course, If you are keen enough, I have used incompatible train and predict templates (Classification and Regression Forest). This was just a way to check that by mistake, the same template wasn’t being used. This was fixed, and we now have LinearRegression, and Classification Forest as well! (2/?? done!)
Offset
I realised there was still something in SELECT that needs to be worked on – loading data from logical files.
The syntax currently looks like this
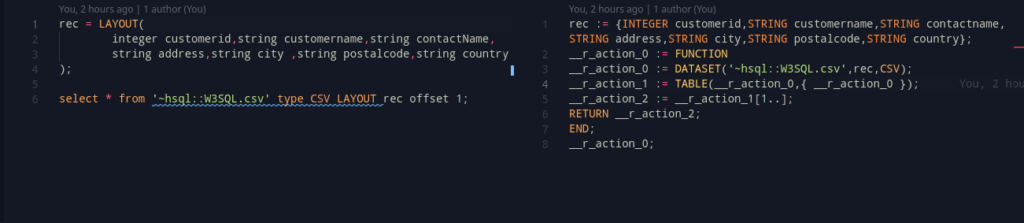
SELECT * from '~file.csv' TYPE CSV layout l1;
Now, in ECL, a common pattern is to use
DATASET('~file.csv',l1,CSV(HEADING(1)));
This removes the header part. The best way, for us is to use the offset clause. But, currently, it is only allowed a suffix to the limit clause. To deal with this, we can make this both optional.
However, the code generation stays almost the same, except for if only offset is specified. In such a case, we can fall back to using a array subscript method.
For example, offset 1, can translate to [1..]. This works well, and gives us a nice output!
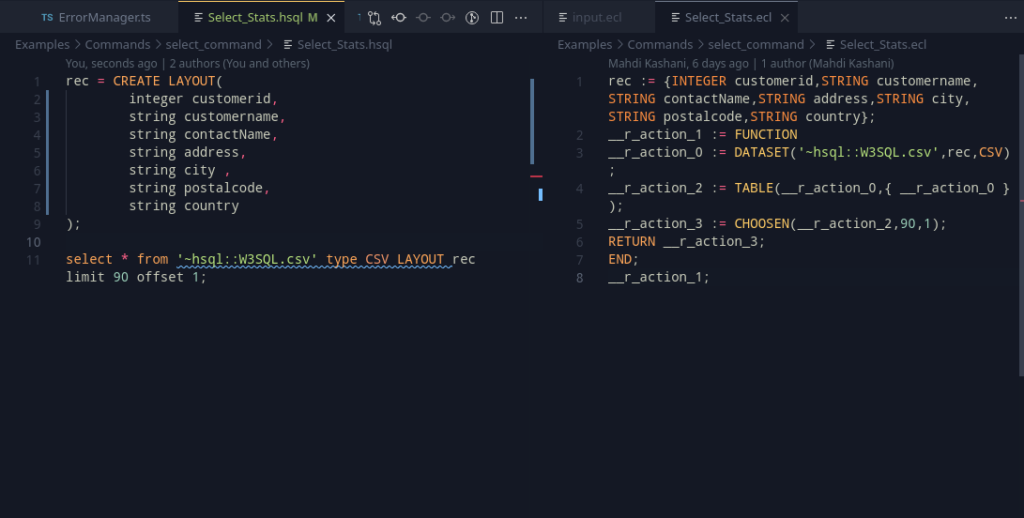
Can you spot a mistake in the offset code?
There’s one small issue though. ECL arrays are 1-indexed. In this case, its trivial too, we can just add a 1, and it’ll work perfectly.
offset 1 hence, should actually become [2..].
Winding up
This completes this week 10 too, and we’re almost there! Now, we can move towards week 11, with the following plans –
Prepare for the final presentation next week
Add more training methods!
Maybe look around and find some nice ways to show the documentation and information about this project. Typedoc is already present in the project, but perhaps Docusaurus or Gitbooks would be good to use!
This week has been a big week – extending SELECT to load up datasets from logical files, modules, functions, and running from a CLI was worked on. There’s a lot to uncover!
Select from dataset
As layouts have now been introduced, one handy way of using select can be added in – loading up a dataset. The idea behind it is similar to how join works in HSQL – a new aliased variable that contains the necessary table. The shape of the table may be made out from the layout that was supplied to the command. Consider the following example:
Select * from '~file::file.thor' layout l1;
This above example selects from the logical file using the layout l1. To see how this would translate to ECL, we can take the following example as what we want to achieve –
__r__action_x :=FUNCTION
src1 := DATASET('~file::file.thor',l1,THOR);
res := TABLE(src1,{src1});
return res;
END;
__r__action_x; // this is the end result-> assign it if needed
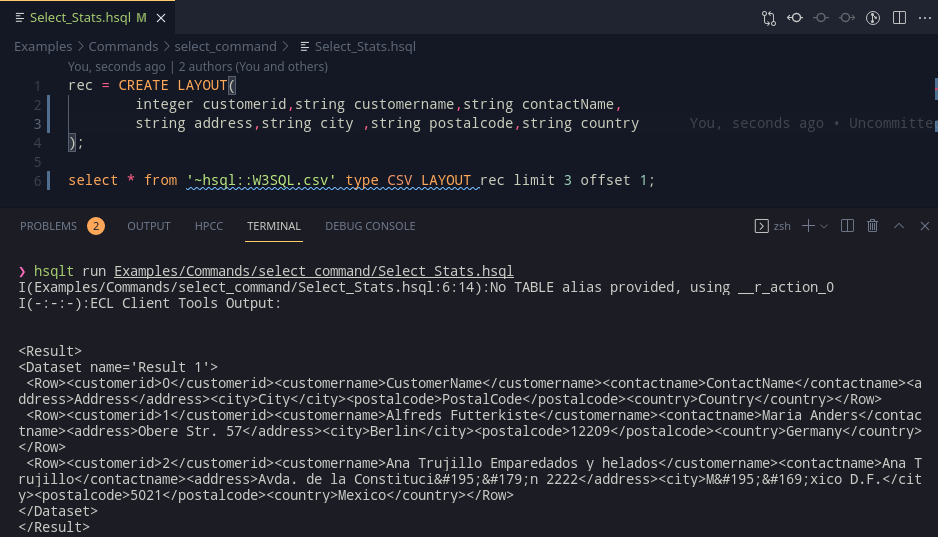
Taking a look at SELECT, we can add support for ECL’s 4 supported types – XML, JSON, CSV, THOR. THOR is relatively easy to work with, but CSV files very commonly need to have their headers stripped (CSV(HEADING(1)) more precisely, when writing the ECL Code). This, might be a good point for SELECT’s offset clause to fit in. Currently it can only work with limit, but that restriction can be lifted later (by falling back to array subscripting).
Adding this SELECT Dataset as a separate node for the AST, we can treat it just like a join, and voila!
We can select from a dataset!
Modules
Modules are a great way to represent and structure code. Thankfully, as we’ve worked with select, the modelling style is similar here. The variable table entry for modules already exist, so its just a matter of adding in the right syntax. A good one to start would be
x = create module(
export k = 65;
shared j = 66;
l = 67;
);
Currently the grammar still includes ECL’s three visibility modes, but we will look at that later.
When creating an AST node, we can create a new scope, and put our new variables in to create the module before popping them off to create the module entry; and while I thought this was easier, this was more of a “easier said than done”. However, thankfully, it didn’t take much longer since as I had mentioned, the data types were already in place.
And… modules!
The variable table (or symbol table in regular compiler literature) can already resolve by the dot notation, so the type checking it works seamlessly and translates identically without any problems to ECL.
Functions
Functions are intended to be a nice way to reuse code. Implementation wise, they look pretty intimidating. How to start?
Well, let’s start at the grammar
create function <name> ([args]){
[body];
return <definition>;
};
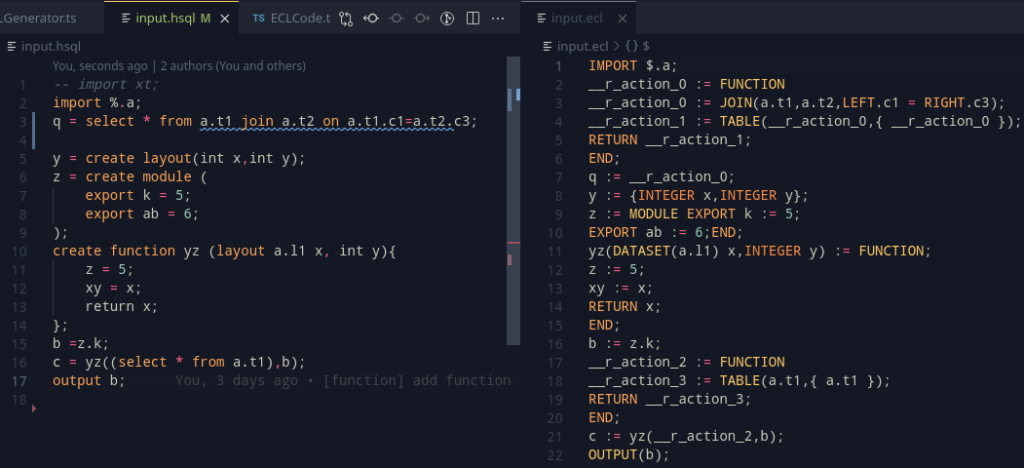
This is something to start with; it looks simple to work with and implement for the grammar. Going into the specifics, we can look at the arguments – there can be two types – the usual default primitive arguments, and a table. For the former, the standard C type rules work, for layouts, we can define them somewhat like this example:
create function yz(layout l1 x,int y){
//...
};
So, an important thing here, is to actually resolve this layout. Once we realise the layout, we can work with AST generation for the function in a way similar to that of the select statement – we can push a new scope into the function, and thankfully, as ECL supports variable shadowing for functions, we can push in the arguments as variables into the scope. Once that is over, we can pop the scope, and the resultant variables are gone! The arguments and the result type needs to be stored by the datatype though, and a function needs to be represented in the variable table too.
Adding all this in, only does half the job. Now that there’s functions, there needs to be a way to call them.
Function call
Function calls are rather important to be able to execute them. Now, the easiest is to model it after most of the programming languages:
x = somefunction(y,z);
This function call can be checked during the AST Generation steps by the following steps:
Locate the function from the variable table. If it cannot be found, throw an error.
Match the function arguments. Does the length and the types match? If no, throw (lots of) errors.
The function call node evaluates to the return type of the function now.
From here, the assignment node takes care of the returned type from there.
Adding all these steps, we can get something marvelous –
Functions and Function calls! Finally (The example also shows passing a select statements results into the first argument)
Running
HSQLT already consults eclcc for getting the paths; this is a good opportunity to use this functionality to extend this and use ecl to compile and submit the resultant .ecl program. After checking if the outputs were produced from the previous code generation stage onto the filesystem, we can take the mainfile which stores the entry point for parsing, and submit that file’s ecl program to the cluster using the client tools. Using some nice stream processing, we can project the stdout and stderr of the child ecl process and get this nice result:
An easy way to run the programs now!
And there’s still more to go. Going over to the extension:
Code completion – Snippets
Snippets are an easy way to work with programs. VSCode snippets are a first step towards code completion. The example below can be typed with a simple write and the line will be filled in. Using TAB, the statement can be navigated and the appropriate sections can be filled in.
Write Snippets
Code completion – Variable Resolving
Variable resolving can be combined with Snippets to allow the user to write programd faster and more effectively. Pressing Ctl+Space currently brings up the current program’s table for auto complete. This, can be added by storing the last compilation’s variable table, and using that to find the possible variable entries.
We can see the variables!
Wrapping up
Oh dear, that was a lot of things in one week. The plans for the next week can roughly be summed up as –
Look into implementing TRAIN and PREDICT statements for Machine Learning.
Look into code generation, fix any glaring issues that result in incorrect code generation.
This week was focused on creating EXPORT/SHARED to work, and to add over importing from current directory and Layouts.
Exports
Exports are a very useful feature in any language. The main idea here is to export some data and layouts, that can be reused in another module. Taking a piece from ECL, we can define two such export modes: SHARED and EXPORT. Let’s take a look at the example below:
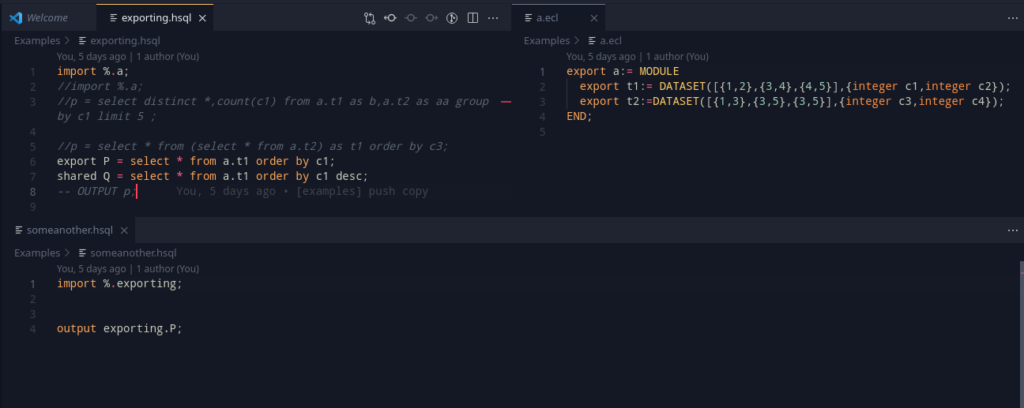
export x = select * from table1;
export y = select * from table2;
This should export out x and y so that it may be used outside. A key note to be made is that unlike ECL, the export <filename> := MODULE should autowrap the program.
There are two possible ways of solving this. One is to write a visitor that can decide whether there is a need to export the module, or we can offload the work to the parser, using a grammar action.
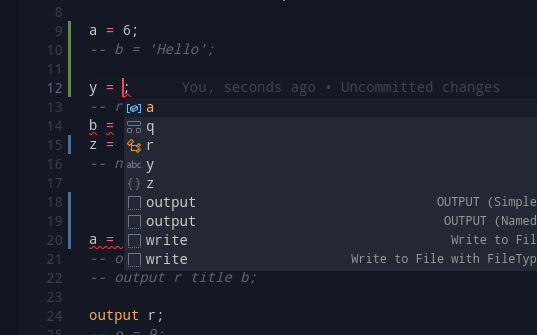
This above grammar accepts a scoped definition. Instead of doing the computation on the visitor/AST Generation side, we can use locals to get this value by the end of the parsing process itself.
This is a quick and easy way to set the program to decide whether it will be wrapped as a module.
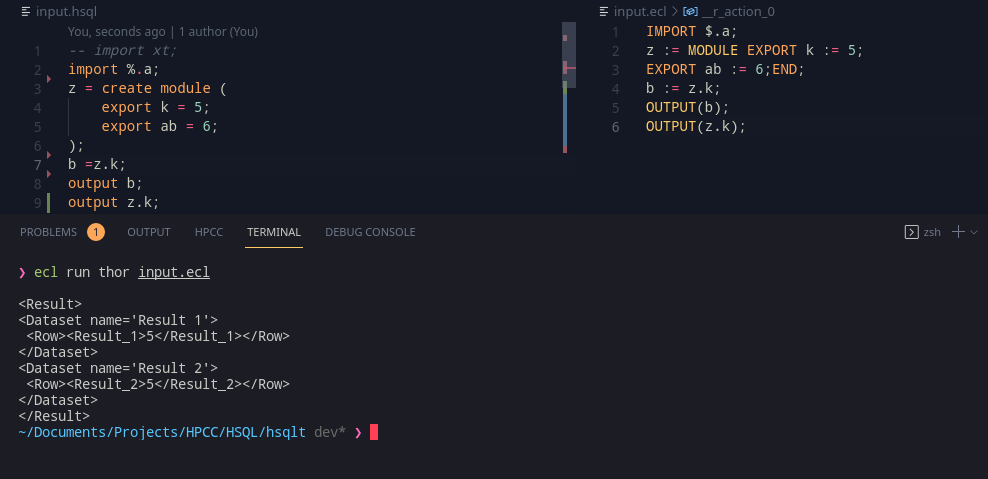
Proceeding further with this, this setup does yield an interesting use – since the variable names in an exported ECL module is the same as that of the window, we can actually import translated hsql files from an ECL file and use it the same way!
Imports from the current directory
ECL has a $ operator which can be used in imports to refer to the current directory. Although grammar support has been there for it in HSQL, the compiler would read and only use the % operator (which performs the work of the $ operator from ECL) as an indication for whether the standard libraries could be skipped or not.
This implementation requires proper file location information is passed into the AST Generator, which allows us to Import modules as required. This also adds support for detecting cyclic imports (which are not allowed in ECL either). This can be added in via the presence of an include stack.
The idea of an include stack, is to present a stack, where the top of the stack will represent the current file being processed. Once this is over, the file is popped. Hence, to detect an include cycle, it is trivial to check if the file is already present in the current include stack.
Adding all this in, we get a nice example that summarizes the work:
Exporting!
Layouts
From here, the work shifted onto layouts. Although not explicitly a goal, layouts are an important precursor to functions and for select. Looking at the syntax of the CREATE TABLE syntax in SQL, we can work with and add a layout with an example syntax as:
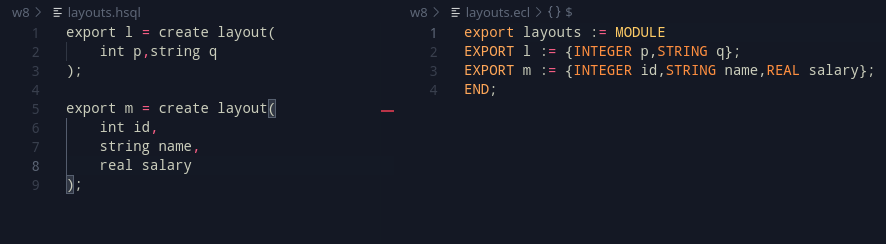
x = create layout(
int p, string q
);
The data type is kept in the front to allow people from other languages to be familiar with it (Hint: C/C++/C#/Java/JS)
Internally, a layout represents a RECORD. After adding them in, they look somewhat like this:
Layouts
Layouts are represented in the Variable Table (Commonly referred as symbol tables in usual compiler terminology) as their own separate term, and can be used to create tables. This, is actually thankfully trivial as the contents of a layout are identical to that of a table, Col elements. With a deep clone of its children, we can create a corresponding table. This will come in use as more features get added into the language.
Wrapping up for the big week ahead
There were some key precursor elements that were made this week, and the syntaxes of Module and Function have been defined, and the idea is to start working on them from here on out. The rough plan for next week is-
Work with layouts
Add in modules
Add in support for functions
Prepare some more examples for showing the functionality of HSQL.
This week’s work was on getting the WRITE statement to work, and extending a DISTRIBUTE extension to SELECT. The rest, was getting some bugfixes and reading.
Write
The OUTPUT statement in HSQL is intended to be a way to output values to a workunit. In ECL however, OUTPUT can be used to write to a workunit as well as to a logical file. In HSQL, it is better to bifurcate the process into two separate commands. With this, the idea behind the WRITE statement, is to allow writing datasets into the logical file.
ECL can support outputs of 4 types – ECL, JSON, THOR, CSV. Typescript enums are a great way of supporting this:
export enum FileOutputType {
THOR,
CSV,
JSON,
XML,
}
// get the enum value
const y = FileOutputType.THOR;
// y is 0
// get the string
const z = FileOutputType[y];
// z is 'THOR'
The enums provide a two way string and integer conversion; which is convenient for storing the two representations while still being good computationally.
Adding in the AST and Code generation stages, we can test out some examples:
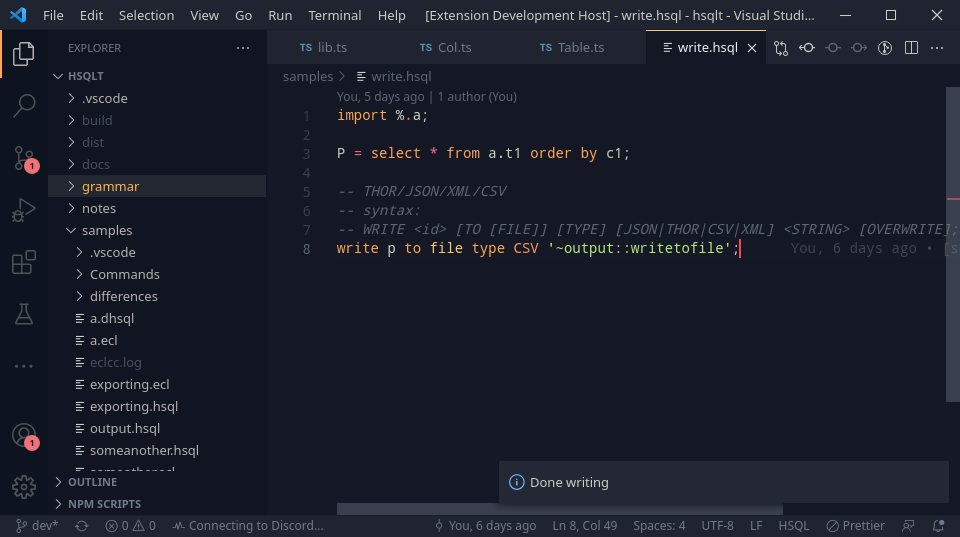
-- hsqlt make Commands/write_command/write.hsql
import %.a;
P = select * from a.t1 order by c1;
-- THOR/JSON/XML/CSV
-- syntax:
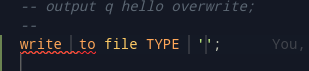
-- WRITE <id> [TO [FILE]] [TYPE] [JSON|THOR|CSV|XML] <STRING> [OVERWRITE];
write p to file type CSV '~output::writetofile.csv';
-- to thor files
write p to file type THOR '~output::writetofile.thor';
-- to xml
write p to file XML '~output::writetofile.xml';
This gives a nice way to write files to output so they can be used outside too.
DISTRIBUTE extension of SELECT
DISTRIBUTE in ECL is used to distribute data across nodes, for further computation; it is really helpful for managing data skew as we go along with further computations.
The idea for it is to be added as an extension in the HSQL select statement with the grammar being:
DISTRIBUTE BY <col1>[,<col2>,...]
This will add a DISTRIBUTE element to the end of the SELECT pipeline which will aid in managing data skew.
a = select * from marksmodule.marksds where marks>40 distribute by marks,subid;
The output for this expression looks like this:
__r_action_0 := FUNCTION
__r_action_1 := marksmodule.marksds( marks > 40);
__r_action_2 := TABLE(__r_action_1,{ __r_action_1 });
__r_action_3 := DISTRIBUTE(__r_action_2,HASH32(marks,subid));
RETURN __r_action_3;
END;
aa := __r_action_0;
The __r_action_3 is a computation that obtains the distributed definition and this is returned in that context. HASH32 has been recommended for use as per the documentation when distributing by expressions/columns, and was chosen as it would be the most used way of distributing that still maintains even distribution.
Bugfixes for the extension
Seems like the extension was lagging behind HSQLT. This is from the previous update that added in the file system reading. As the file locations have to now be provided separately, the Extension had not yet been configured for it. Additionally, the extension’s client and servers work on different folders. Due to this, the server can successfully locate files, whereas the client fails to. This required support for the compiler to refer to another directory ‘offset’ from the current directory (This has been added to the CLI tool as a -b flag). Adding this and support for %, allows HSQL to be used with the extension a bit more easily.
Writes, clean outputs and no more ‘Warnings’!
Demo
As there was a demo that was done at the end of this week, various examples have been created to show how HSQL may be used. Currently, they do not showcase actual usecases, but only the syntax and the usability of the language. Nearly all supported features have been enumerated and the plan is to have a nice set of examples for each statement going ahead. The demo actually revealed some good to have feedback and the plan is to work towards getting some more statements and features as we go along.
Wrapping up
As Week 7 is coming to wraps, the plan is to work on these for Week 8:
Add support for exporting definitions
Add support for bundling definitions into modules in HSQL
Look into procedure syntaxes in HSQL
Evaluate existing featureset and make some examples to work on performance and correctness.