HPCC Systems is a high-performant, enterprise-ready open-source supercomputing platform (Check out their Official Page and their Github organization).
Maybe a better way of putting it is, it provides a really easy way to perform data cleaning, transformation, aggregations (and most other tasks you may need with big data) in an efficient and distributed fashion. But of course, that description only touches its capabilities and what work is being done with it.
HPCC Systems and ECL
So how would one use this entire system? Here’s one way. You can write up what you need the system to do, in a language called ECL. Its a really powerful declarative language that can allow you to write fast, expressive code that deals with data (or rather, how to deal with data). Here’s a nice example that shows how you may use ECL:
// The layout of your data
myDataLayout := RECORD
UNSIGNED id;
STRING16 firstName;
STRING16 lastName;
END;
// Load up your data from '~myscope::names.csv', a (logical) file that is distributed/sprayed onto the system
myData := DATASET('~myscope::names.csv',myDataLayout);
// sort the data by firstName
sorted := SORT(myData,firstName);
// output like the first ten for our display sake, some people might save the whole output to somewhere else completely
OUTPUT(CHOOSEN(sorted,10));The language is also very data-centric, if you can notice from the example above. This stress on the flow of data allows programs made with ECL to be aggressively optimized and parallelized.
(H)SQL
ECL as a language targets powerful data processing and transformation, but some people, may prefer the simplicity and familiarity of SQL. In fact, SQL is already present as a usable language in HPCC Systems. However, it is as an embedded language, and still requires the use of wrapping ECL.
So here, our idea has been to present HSQL, a SQL-like language, that should serve as a nice entry point for data analysts and newcomers into HPCC Systems. Here’s a brief look at idea at what the syntax is designed to look like:
IMPORT xyz; // imports should be a familiar concept from other languages
myPeopleData = SELECT * from xyz.peopleData;
sortedFirstPart = SELECT * from myPeopleData ORDER BY firstName LIMIT 10;
OUTPUT myPeopleData;For many people who are used to SQL and other languages, this may seem more natural and easier to grasp. This SQL-inspired language is intended to translate completely to ECL, so most code can be interfaced with it no-problem, and people can work in projects using both ECL and HSQL. Of course, as they get used to the power and the effectiveness of ECL, they may choose to shift over to using ECL more, but the journey should be relatively smooth. (There’s some more syntaxes that are ML-specific, but I’ll leave them for later)
HSQL – Last year
I’ve been working on HSQL since last year; it started as a project from LexisNexis Risk Solutions, and we’ve been working hard since then.
Here’s how it was working back then:
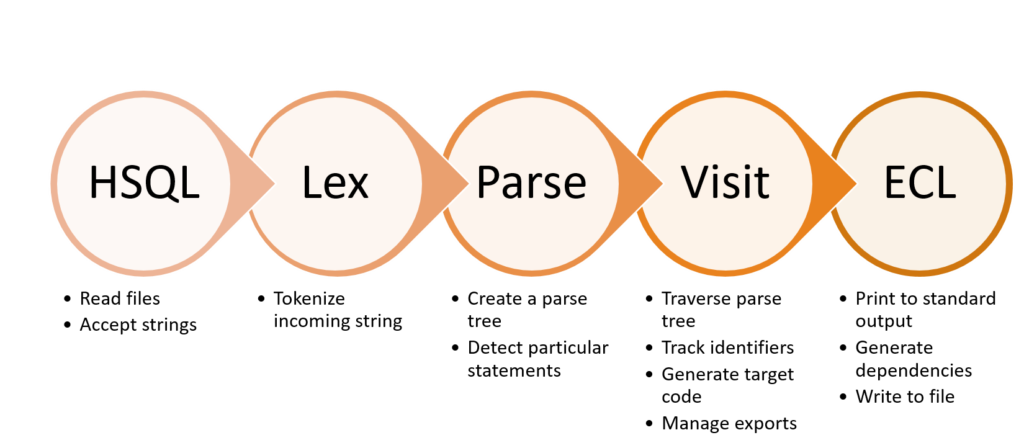
We used ANTLR, and how it works is that you can enter your grammar, and it generates lexers (program that will scan a input text and chop it up into tokens) and parsers (who will take these tokens and try to get some structure out of the tokens). Our project was based on Javascript, as HSQL is also intended to work in cloud environments. Here’s a good example of how parse trees look from ANTLR look like (I use the ANTLR extension from the VSCode Marketplace for visualization):
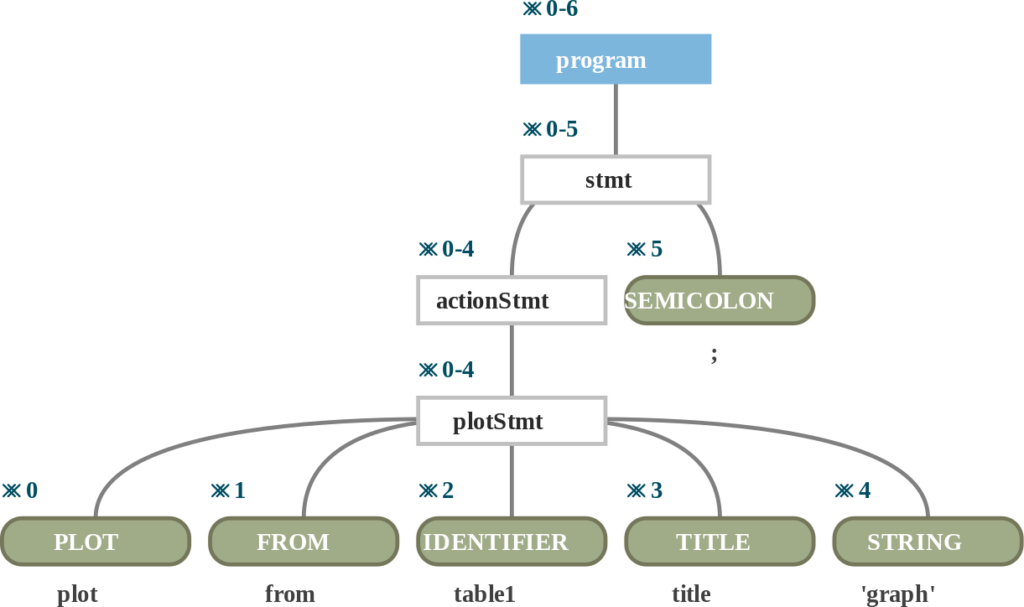
plot from table1 title 'graph';ANTLR allows us a nice way to traverse these parse trees (Called listeners and visitors, the latter essentially being an implementation of the Visitor Design Pattern). Using this, we can check if the program entered is semantically right, and then try to generate the ECL Code for it. Wrapping up this whole process in a nice looking tool, and wrapping that up further in a IDE extension, we were able to use it as a good base for how HSQL can work.
HSQL
Somewhere around last year, I had submitted a proposal to work further on HSQL to the HPCC Systems Summer Internship Program, to bring in key changes and enhancements that should make it a more extensible language. I was really happy when they let me know that they had accepted my proposal and were offering me an internship for the summer period. Here are some of the key points that I will be planning to work upon:
- Introduce an AST building phase where semantic validation can be done. This is really important as ANTLR does not like tree-rewriting (as of writing this) and can misbehave. Additionally, this also splits out code generation as a separate phase of the translation, which is useful especially when used in an IDE.
- Improve the interface of HSQLC for use in IDEs and as a standalone CLI tool.
- Add in some nice syntax for merges and filtering.
Working on HSQL
I have been working alongside my mentor to getting things ready for a while, and this is a brief summary of the changes I’ve made till now:
- Migrate to Typescript: Coming off from finishing the project, I realized that a big project like HSQLC requires documentation, and a strong emphasis on types. Hence, having a strongly-typed foundation to the project helps maintain some sense of the project when you refer to your own code a few months down the line.
- Introduce an AST generation stage: Splitting the then one shot goal of code generation into a pass of AST which some semantic validation followed by Code generation should simplify processing and also make it more IDE-friendly (In IDEs, we don’t need to proceed beyond the AST generation stage, as code generation is not really that useful there). Although this is in-progress, this should be helpful
- A slight better framework on testing: Last time around we had focused on testing the final ECL syntax only. Although that is a fair kind of test to do, this time around I believe it should be better to test individual components as they are being built up.
- Slightly more natural CLI tool: Use commands from yargs instead of flags, this resembles the way programs like compilers are normally called.
This should serve as a good base for my 12-week period of work on HSQL. And now, it is time to start!