I started work on the extension first. Needing some changes, I needed two primary features: Syntax checking, and compiling to ECL as a primary featureset. So, I decided to go in order. For syntax checking, the basic process is:
- The language client keeps sending info about the text documents on the IDE, to the language server.
- The language server can act on these, and at its discretion, can send diagnostics.
There is a text document manager that is provided by the example implementation, but it does not emit any information about incremental updates, but rather provides the whole document itself.
Thankfully, enough configurability is present, to make your own text document manager. Using the standard document reference, I added the ability to add some listeners for incremental updates.
From there on out, I could check if the incremental updates would warrant a change in diagnostics (currently which i set to always update anyways) and then, push it to HSQLT to correct. Receiving the corrections, one can map the issues to the files, and the diagnostic severity levels; and then done! Pretty errors!
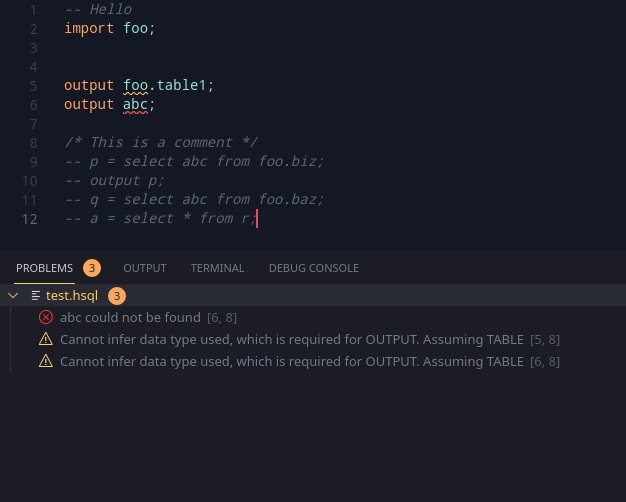
The second part was rather simple, which was a compile command. Adding in a simple UI for confirming if the user wants outputs in case of warnings or errors, and writing it to the disk in that case, we get a nice little compile command (just remember to force VSCode to save all the files).
We can now pause most of the work on the extension, as this will work for testing the majority of HSQL. Once further progress is made on the language side, we can try working on ECL integration or some datatype highlighting.
Pretty diagrams
So I finally got around to updating the general architecture of what the current version of HSQL looks like and, here:
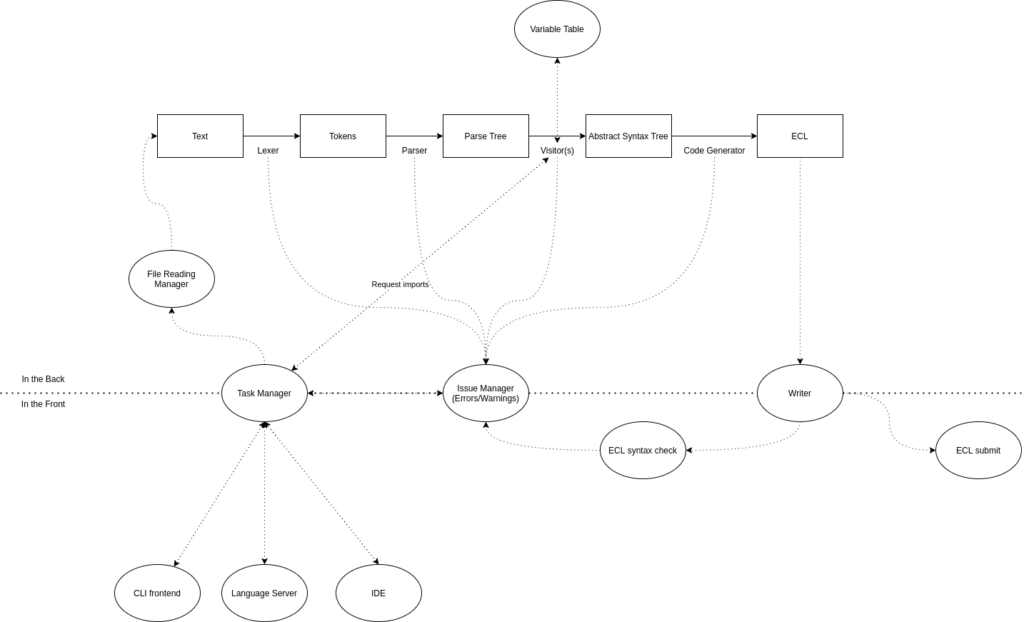
Lots of arrows here and pretty ideas aside, the current repository is meant to be used as an executable, as well a library. This should make it easy to create extensions based on the system, or even extend it later easily.
Packaging
Both hsqlt and the vscode extension are intended to be packaged before use. hsqlt has been configured to use pkg, and producing executables is very easy.
The VSCode extension though. I run a vsce package and I am greeted with:
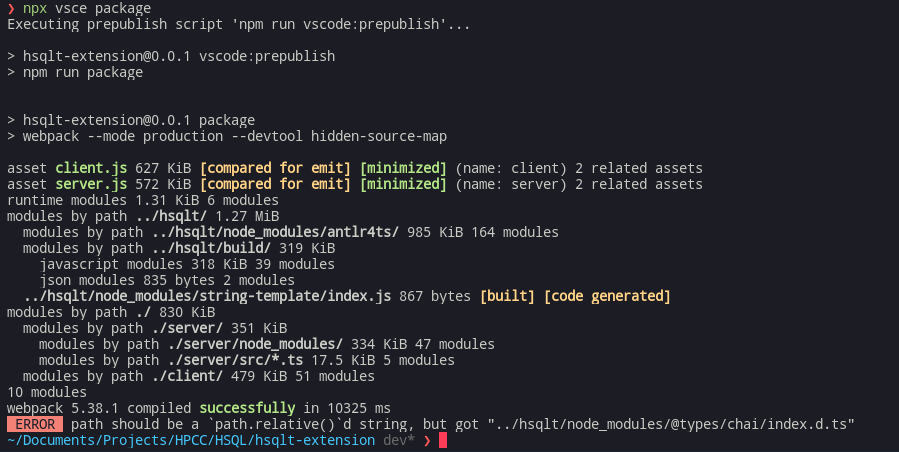
Why is it trying to access the other project? I thought it was under .vscodeignore. Here’s some context, the extension and the compiler repo are located in a parent folder, and the compiler is linked to my global npm scope, and then linked back to this repo.
Digging further in the code, I open a Javascript Debugger Terminal, and see that it is from the ignore module. The module attempts to index which files to ignore, and follows symlinks. Adding to it, it also does not like accepting files which are outside the current folder (which we have here). And voila, the error. I have filed an issue under vsce and I hope to see some way around this. Worst-case scenario, I can unlink the repo before packaging (which might even work).
Select – Playing with scope
Select is a bit of a complex statement in SQL. The fact that it can call itself scares me, and having to deal with aliases is also scary. With aliases in mind, I got an idea – scoping. My mentor had mentioned earlier to think about procedures and syntax, and I have been working on scoping, knowing that I’d have to use them eventually. Interestingly, SQL Table aliases behave like a locally scoped definition; so perhaps table aliases can be mimicked with scoping.
Now how to enforce scoping? Functions come to mind. ECL Functions are similar to the usual program functions, save one critical difference – no variable shadowing. If a definition is declared, it cannot be shadowed in an easy way. So, time to go about it in a step by step way. How can I emulate a select query in ECL? I came up with this program flow for what the ecl should be shaped like
1. From - Create a gigantic source table from all the sources.
a. Enumerate all the sources - the usual code generation
b. apply aliases - redefine them
c. Join them - JOIN
2. where - Apply a filter on the above table
3. sort - sort the data from above
4. Column filters and grouping - Use TABLE to do grouping and column filtering
5. apply limit offset from SQL - Use CHOOSEN on the above result
6. DISTINCT - DEDUP the above resultThis method seems rather useful, as there is natural “use the result from above” flow to it. Additionally, with this, there is no way that we will be referring to data that has been deleted by a previous step. Honing this, i came up with this simple pseudo-algorithm –
1. Create a function and assign it to a value
2. Enumerate all the sources that have been changed, or need processing - JOINS, select in select and aliases.
a. JOINS - do a join
b. select in select - follow this procedure and assign it to its alias
c. Aliases - assign the original value to the alias
3. Now, take _all_ the sources, and join them all.
4. Take last generated variable and then do the following in order
a. Where - apply filter
b. sort - sort
c. group and column filters - table
d. limit offset - choosen
e. distinct - dedup all
5. return the last generated variable.
6. The variable assigned to the function on step 1, is now the resultLet’s check this with an example
Here’s a SQL statement:
select *,TRIM(c1) from table1 as table2;Here’s an idea of what the SQL would look like
__action_1 := function
// inspect the sources - define all aliases
table2:= table1;
// the base select query is done - * from SELECT becomes the referenced table name
__action_2 := TABLE(table2,{table2,TRIM(c1)});
// return the last generated variable - __action_2
return __action_2;
end;
__action_1; // this gives the output of the functionSeems pretty strange, yes. But I’ll be working on this next week, and we shall see how far things go.
Wrapping up for the week
With quite a bit of work done this week around, the plan is to pick up the following on the next week:
- Select AST+Codegeneration. Getting them ready as soon as possible is very important to getting things to a usable state. This one point alone is probably really large, as it involves getting a lot of components right to function completely. (In fact, I expect this to take quite a while.)
- Looking at syntaxes from other SQL/-like languages.