This week’s work is planned exclusively around getting select to work; its a huge part of the language. The decision, was to use FUNCTIONS, to emulate a SELECT. Why? Because functions in ECL have their own scoping, and local variables declared there, will be usable outside the scope of the function. However, a function cannot shadow variables that exist. Selects, have aliases, which can perfectly be matched by local function-scoped definitions, and can help skip the entire process of defining “formal” (visible variable name) and the “behind the scenes” variable names.
The idea
The idea is a simple 6 step process:
- Create a function and assign it to a value
- Enumerate all the sources that have been changed, or need processing – JOINS, select in select and aliases.
- JOINS – do a join
- select in select – follow this procedure and assign it to its alias
- Aliases – assign the original value to the alias
- Now, take all the sources, and join them all.
- Take last generated variable and then do the following in order
- Where – apply filter
- sort – sort
- group and column filters – table
- limit offset – choosen
- distinct – dedup all
- Wrap this whole block of statements in a function, returning the last generated variable.
- The variable assigned to the function on step 5, can now be the result. (assign it or just use it as an action)
From
The current syntax supports three kinds of data sources:
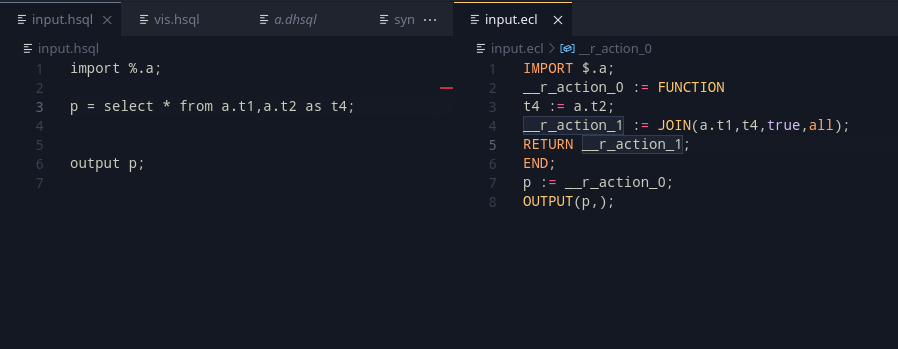
- Select statements – The statements can have a SELECT statement as part of a table source. To ease our worries and pain, SQL mandates that such sources have a defined alias. Whew. The idea for these, is to run this algorithm (read as: thank god recursion exists) for generating the select statement, and assign it to this select statement.
- Table Definitions – The statements can refer to table definitions and also have an alias. This is a simple case of a redefinition if a reassignment happens.
- Joins – Joins are a part of SQL, where there is a specific join type, and an expression that helps the join. Unfortunately joins do not have an alias, and this brings us to an annoyance – we need to force create an alias and let the user know in that case.
The multiple datasets are then joined, and the result variable is put on a stack. What happens from here on, is based on the order above. the top of the stack’s variable is used to generate a new variable, which is then placed on the top. This keeps the optional parts actually optional and generates the definitions only as necessary.
Implementing the from part, we get some interesting outputs that work well!
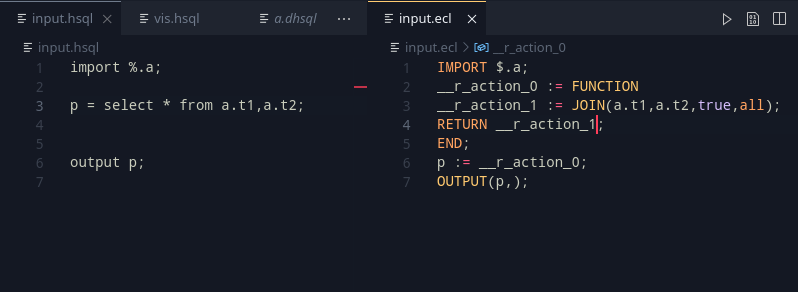
From here, the rest of the statements can be added in. The column filtering is important, as they are the only other mandatory part of select.
The rest of SELECT
The rest of the select, uses the last generated variable, and creates a new one.
Making some of them, here’s what we get:
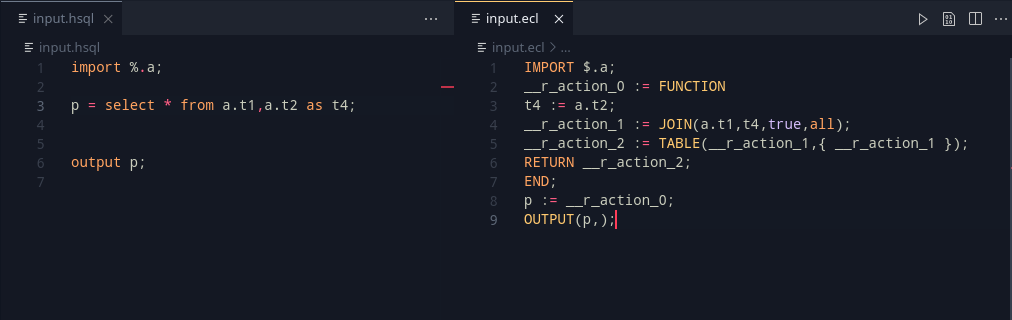
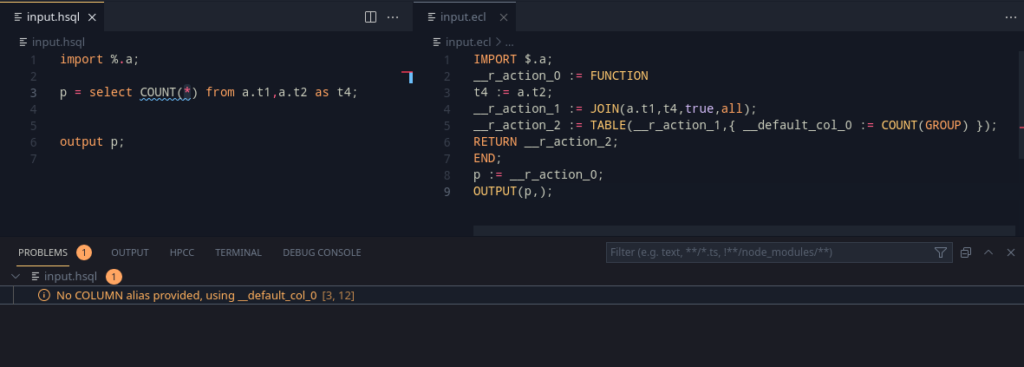
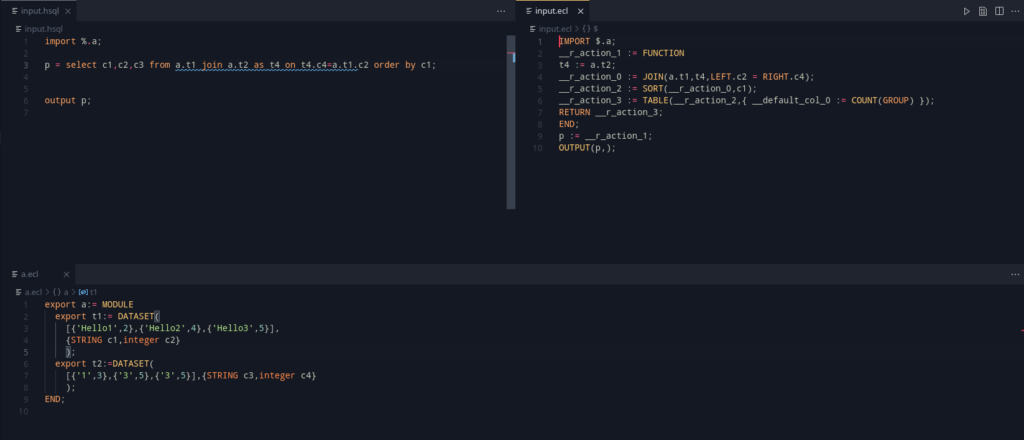
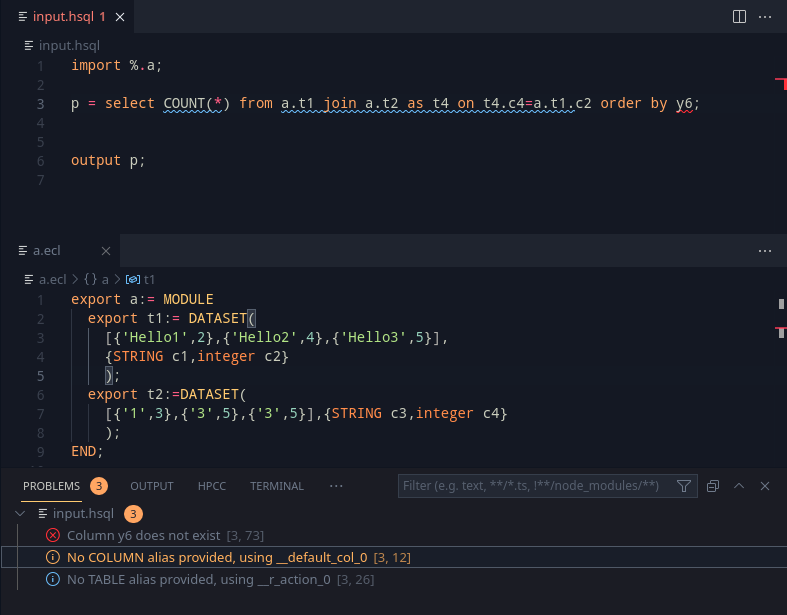
Looking at the grammar, the ORDER BY, GROUP BY, WHERE was added in. That’s a lot of querying capabilities as part of one sentence.
The having query segment was considered, but dropped as it can be done by two queries (Another where after the group by).
Winding up
This took a good part of the week. Adding the support code did take a bit of the time, but this allows us to use the most important part of SQL. The plan for the upcoming week is as follows:
- Start looking at import resolution. Imports need to be vetted to make sure that there exists atleast a folder, .ecl file or a HSQL file.
- HSQL might need a way to do auto imports for certain core modules such as
VisualizerandML_Core(for Plots and for Machine learning related statements). This should help with ease-of-use. - Plots – The plot statement is another important objective as visualizing is an import usecase for HSQL. The idea is to support basic and important visualization methods, and try to find out if there’s a way that other modules can integrate into HSQL and add to more plot methods.